
Chapter 7. Persistence - JBoss JBPM 3.1.3 userguide 英文版文档
In most scenarios, jBPM is used to maintain execution of processes that span a long time. In this context, "a long time" means spanning several transactions. The main purpose of persistence is to store process executions during wait states. So think of the process executions as state machines. In one transaction, we want to move the process execution state machine from one state to the next.
A process definition can be represented in 3 different forms : as xml, as java objects and as records in the jBPM database. Executional (=runtime) information and logging information can be represented in 2 forms : as java objects and as records in the jBPM database.
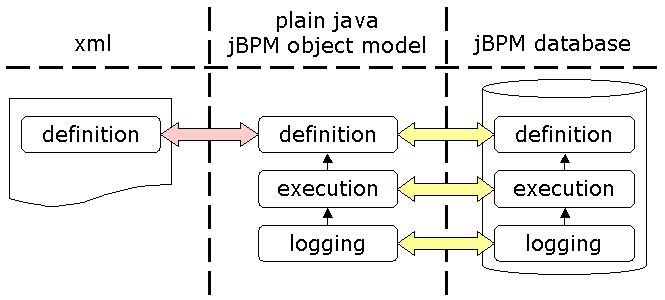
For more information about the xml representation of process definitions and process archives, see Chapter 16, jBPM Process Definition Language (JPDL).
More information on how to deploy a process archive to the database can be found in Section 16.1.1, “Deploying a process archive”
The persistence API is an integrated with the configuration framework my exposing some convenience persistence methods on the JbpmContext. Persistence API operations can therefor be called inside a jBPM context block like this:
JbpmContext jbpmContext = jbpmConfiguration.createJbpmContext();
try {
// Invoke persistence operations here
} finally {
jbpmContext.close();
}In what follows, we suppose that the configuration includes a persistence service similar to this one (as in the example configuration file src/config.files/jbpm.cfg.xml):
<jbpm-configuration>
<jbpm-context>
<service name='persistence' factory='org.jbpm.persistence.db.DbPersistenceServiceFactory' />
...
</jbpm-context>
...
</jbpm-configuration>The three most common persistence operations are:
- Deploying a process
- Starting a new execution of a process
- Continuing an execution
First deploying a process definition. Typically, this will be done directly from the graphical process designer or from the deployprocess ant task. But here you can see how this is done programmatically:
JbpmContext jbpmContext = jbpmConfiguration.createJbpmContext();
try {
ProcessDefinition processDefinition = ...;
jbpmContext.deployProcessDefinition(processDefinition);
} finally {
jbpmContext.close();
}For the creation of a new process execution, we need to specify of which process definition this execution will be an instance. The most common way to specify this is to refer to the name of the process and let jBPM find the latest version of that process in the database:
JbpmContext jbpmContext = jbpmConfiguration.createJbpmContext();
try {
String processName = ...;
ProcessInstance processInstance =
jbpmContext.newProcessInstance(processName);
} finally {
jbpmContext.close();
}For continuing a process execution, we need to fetch the process instance, the token or the taskInstance from the database, invoke some methods on the POJO jBPM objects and afterwards save the updates made to the processInstance into the database again.
JbpmContext jbpmContext = jbpmConfiguration.createJbpmContext();
try {
long processInstanceId = ...;
ProcessInstance processInstance =
jbpmContext.loadProcessInstance(processInstanceId);
processInstance.signal();
jbpmContext.save(processInstance);
} finally {
jbpmContext.close();
}Note that if you use the xxxForUpdate methods in the JbpmContext, an explicit invocation of the jbpmContext.save is not necessary any more because it will then occur automatically during the close of the jbpmContext. E.g. suppose we want to inform jBPM about a taskInstance that has been completed. Note that task instance completion can trigger execution to continue so the processInstance related to the taskInstance must be saved. The most convenient way to do this is to use the loadTaskInstanceForUpdate method:
JbpmContext jbpmContext = jbpmConfiguration.createJbpmContext();
try {
long taskInstanceId = ...;
TaskInstance taskInstance =
jbpmContext.loadTaskInstanceForUpdate(taskInstanceId);
taskInstance.end();
} finally {
jbpmContext.close();
}Just as background information, the next part is an explanation of how jBPM manages the persistence and uses hibernate.
The JbpmConfiguration maintains a set of ServiceFactorys. The service factories are configured in the jbpm.cfg.xml as shown above and instantiated lazy. The DbPersistenceServiceFactory is only instantiated the first time when it is needed. After that, service factories are maintained in the JbpmConfiguration. A DbPersistenceServiceFactory manages a hibernate SessionFactory. But also the hibernate session factory is created lazy when requested the first time.
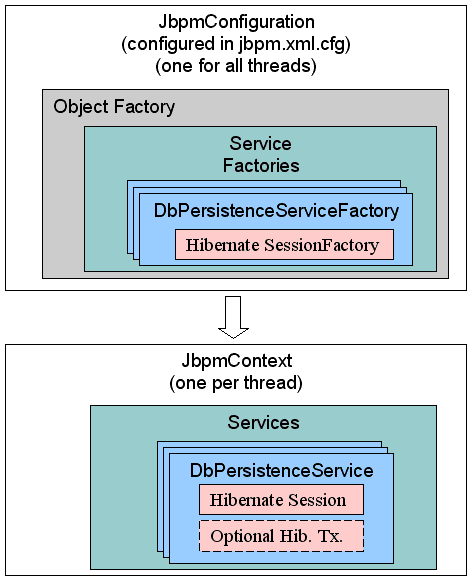
During the invocation of jbpmConfiguration.createJbpmContext(), only the JbpmContext is created. No further persistence related initializations are done at that time. The JbpmContext manages a DbPersistenceService, which is instantiated upon first request. The DbPersistenceService manages the hibernate session. Also the hibernate session inside the DbPersistenceService is created lazy. As a result, a hibernate session will be only be opened when the first operation is invoked that requires persistence and not earlier.
The DbPersistenceService maintains a lazy initialized hibernate session. All database access is done through this hibernate session. All queries and updates done by jBPM are exposed by the XxxSession classes like e.g. GraphSession, SchedulerSession, LoggingSession,... These session classes refer to the hibernate queries and all use the same hibernate session underneath.
The XxxxSession classes are accessible via the JbpmContext as well.
By default, the DbPersistenceServiceFactory will use the resource hibernate.cfg.xml in the root of the classpath to create the hibernate session factory. Note that the hibernate configuration file resource is mapped in the property 'jbpm.hibernate.cfg.xml' and can be customized in the jbpm.cfg.xml. This is the default configuration:
<jbpm-configuration>
...
<!-- configuration resource files pointing to default configuration files in jbpm-{version}.jar -->
<string name='resource.hibernate.cfg.xml'
value='hibernate.cfg.xml' />
<!-- <string name='resource.hibernate.properties'
value='hibernate.properties' /> -->
...
</jbpm-configuration>When the property resource.hibernate.properties is specified, the properties in that resource file will overwrite all the properties in the hibernate.cfg.xml. Instead of updating the hibernate.cfg.xml to point to your DB, the hibernate.properties can be used to handle jbpm upgrades conveniently: The hibernate.cfg.xml can then be copied without having to reapply the changes.
Please refer to the hibernate documentation: <a>http://www.hibernate.org/214.html</a>
The DbPersistenceServiceFactory itself has 3 more configuration properties: isTransactionEnabled, sessionFactoryJndiName and dataSourceJndiName. To specify any of these properties in the jbpm.cfg.xml, you need to specify the service factory as a bean in the factory element like this:
<jbpm-context>
<service name="persistence">
<factory>
<bean factory="org.jbpm.persistence.db.DbPersistenceServiceFactory">
<field name="isTransactionEnabled"><false /></field>
<field name="sessionFactoryJndiName">
<string value="java:/myHibSessFactJndiName" />
</field>
<field name="dataSourceJndiName">
<string value="java:/myDataSourceJndiName" />
</field>
</bean>
</factory>
</service>
...
</jbpm-context>- isTransactionEnabled: by default, jBPM will begin and end hibernate transactions. To disable transactions and prohibit jBPM from managing transactions with hibernate, configure the isTransactionEnabled property to false as in the example above. For more info about transactions, see Section 7.3, “Hibernate transactions”.
- sessionFactoryJndiName: by default, this is null, meaning that the session factory is not fetched from JNDI. If set and a session factory is needed to create a hibernate session, the session factory will be fetched from jndi using the provided JNDI name.
- dataSourceJndiName: by default, this is null and creation of JDBC connections will be delegated to hibernate. By specifying a datasource, jBPM will fetch a JDBC connection from the datasource and provide that to hibernate while opening a new session. For user provided JDBC connections, see Section 7.5, “User provided stuff”.
By default, jBPM will delegate transaction to hibernate and use the session per transaction pattern. jBPM will begin a hibernate transaction when a hibernate session is opened. This will happen the first time when a persistent operation is invoked on the jbpmContext. The transaction will be committed right before the hibernate session is closed. That will happen inside the jbpmContext.close().
Use jbpmContext.setRollbackOnly() to mark a transaction for rollback. In that case, the transaction will be rolled back right before the session is closed inside of the jbpmContext.close().
To prohibit jBPM from invoking any of the transaction methods on the hibernate API, set the isTransactionEnabled property to false as explained in Section 7.2.3, “The DbPersistenceServiceFactory” above.
The most common scenario for managed transactions is when using jBPM in a JEE application server like JBoss. The most common scenario is the following:
- configure a DataSource in your application server
- configure hibernate to use that data source for its connections
- use container managed transactions
- disable transactions in jBPM
You can also programmatically provide JDBC connections, hibernate sessions and hibernate session factories to jBPM.
When such a resource is provided to jBPM, it will use the provided resources rather then the configured ones.
The JbpmContext class contains some convenience methods to inject resources programmatically. For example, to provide a JDBC connectio to jBPM, use the following code:
JbpmContext jbpmContext = jbpmConfiguration.createJbpmContext();
try {
Connection connection = ...;
jbpmContext.setConnection(connection);
// invoke one or more persistence operations
} finally {
jbpmContext.close();
}the JbpmContext class has following convenience methods for providing resource programmatically:
JbpmContext.setConnection(Connection); JbpmContext.setSession(Session); JbpmContext.setSessionFactory(SessionFactory);
All the HQL queries that jBPM uses are centralized in one configuration file. That resource file is referenced in the hibernate.cfg.xml configuration file like this:
<hibernate-configuration>
...
<!-- hql queries and type defs -->
<mapping resource="org/jbpm/db/hibernate.queries.hbm.xml" />
...
</hibernate-configuration>To customize one or more of those queries, take a copy of the original file and put your customized version somewhere on the classpath. Then update the reference 'org/jbpm/db/hibernate.queries.hbm.xml' in the hibernate.cfg.xml to point to your customized version.
jBPM runs on any database that is supported by hibernate.
The example configuration files in jBPM (src/config.files) specify the use of the hypersonic in-memory database. That database is ideal during development and for testing. The hypersonic in-memory database keeps all its data in memory and doesn't store it on disk.
Following is an indicative list of things to do when changing jBPM to use a different database:
- put the jdbc-driver library archive in the classpath
- update the hibernate configuration used by jBPM
- create the schema in the new database
The jbpm.db subproject, contains a number of drivers, instructions and scripts to help you getting started on your database of choice. Please, refer to the readme.html in the root of the jbpm.db project for more information.
While jBPM is capable of generating DDL scripts for all database, these schemas are not always optimized. So you might want to have your DBA review the DDL that is generated to optimize the column types and use of indexes.
In development you might be interested in the following hibernate configuration: If you set hibernate configuration property 'hibernate.hbm2ddl.auto' to 'create-drop' (e.g. in the hibernate.cfg.xml), the schema will be automatically created in the database the first time it is used in an application. When the application closes down, the schema will be dropped.
The schema generation can also be invoked programmatically with jbpmConfiguration.createSchema() and jbpmConfiguration.dropSchema().
In your project, you might use hibernate for your persistence. Combining your persistent classes with the jBPM persistent classes is optional. There are two major benefits when combining your hibernate persistence with jBPM's hibernate persistence:
First, session, connection and transaction management become easier. By combining jBPM and your persistence into one hibernate session factory, there is one hibernate session, one jdbc connection that handles both yours and jBPM's persistence. So automatically the jBPM updates are in the same transaction as the updates to your own domain model. This can eliminates the need for using a transaction manager.
Secondly, this enable you to drop your hibernatable persistent object in to the process variables without any further hassle.
The easiest way to integrate your persistent classes with the jBPM persistent classes is by creating one central hibernate.cfg.xml. You can take the jBPM src/config.files/hibernate.cfg.xml as a starting point and add references to your own hibernate mapping files in there.
To customize any of the jBPM hibernate mapping files, you can proceed as follows:
- copy the jBPM hibernate mapping file(s) you want to copy from the sources (src/java.jbpm/...) or from inside of the jbpm jar.
- put the copy anywhere you want on the classpath
- update the references to the customized mapping files in the hibernate.cfg.xml configuration file
jBPM uses hibernate's second level cache for keeping the process definitions in memory after loading them once. The process definition classes and collections are configured in the jBPM hibernate mapping files with the cache element like this:
<cache usage="nonstrict-read-write"/>
Since process definitions (should) never change, it is ok to keep them in the second level cache. See also Section 16.1.3, “Changing deployed process definitions”.
The second level cache is an important aspect of the JBoss jBPM implementation. If it weren't for this cache, JBoss jBPM could have a serious drawback in comparison to the other techniques to implement a BPM engine.
The caching strategy is set to nonstrict-read-write. At runtime, the caching strategy could be set to read-only. But in that case, you would need a separate set of hibernate mapping files for deploying a process. That is why we opted for the nonstrict-read-write.