Chapter 4. Graph Oriented Programming - JBoss JBPM 3.1.3 userguide 英文版文档
This chapter can be considered the manifest for JBoss jBPM. It gives a complete overview of the vision and ideas behind current strategy and future directions of the JBoss jBPM project. This vision significantly differs from the traditional approach.
First of all, we believe in multiple process languages. There are different environments and different purposes that require a their own specific process language.
Secondly, Graph Oriented Programming is a new implementation technique that serves as a basis for all graph based process languages.
The main benefit of our approach is that it defines one base technology for all types of process languages.
Current software development relies more and more on domain specific languages. A typical Java developer will use quite a few domain specific languages. The XML-files in a project that are input for various frameworks can be considered domain specific languages.

Domain specific languages for workflow, BPM, orchestration and pageflow are based on the execution of a directed graph. Others like hibernate mapping files, ioc-configuration are not. Graph Oriented Programming is the foundation for all domain specific languages that are based on executing a graph.
Graph Oriented Programming is a very simple technique that describes how graphs can be defined and executed on a plain OO programming language.
In Section 4.5, “Application domains”, we'll cover the most often used process languages that can be implemented using Graph Oriented Programming like workflow, BPM, orchestration and pageflow.
Each process language can be considered a Domain Specific Language (DSL). The DSL perspective gives developers good insight in how process languages are related to plain OO programming.
This section might give the impression that we're focussed solely on programming environments. None is less true. Graph Oriented Programming includes the whole BPM product continuum from API libraries to fully fledged BPM suite products. BPM suite products are complete software development environments that are centered around business processes. In that type of products, coding in programming languages is avoided as much as possible.
An important aspect of domain specific languages is that each language has a certain grammar. That grammar can be expressed as a domain model. In case of java this is Class, Method, Field, Constructor,... In jPDL this is Node, Transition, Action,... In rules, this is condition, concequence,...
The main idea of DSL is that developers think in those grammars when authoring artifacts for a specific language. The IDE is build around the grammar of a language. Then, there can be different editors to author the artifacts. E.g. a jPDL process has a graphical editor and a XML source view editor. Also there can be different ways to store the same artifact: for jPDL, this could be a process XML file or the serialized object graph of nodes and transition objects. Another (theoretic) example is java: you could use the java class file format on the system. When a user starts the editor, the sources are generated. When a user saves the compiled class is saved....
Where ten years ago, the biggest part of a developer was spend on writing code. Now a shift has taken place towards learning and using domain specific languages. This trend will still continue and the result is that developers will have a big choice between frameworks and writing software in the host platform. JBoss SEAM is a very big step in that direction.
Some of those languages are based on execution of a graph. E.g. jPDL for workflow in Java, BPEL for service orchestration, SEAM pageflow,... Graph Oriented Programming is a common foundation for all these type of domain specific languages.
In the future, for each language, a developer will be able to choose an editor that suites him/her best. E.g. a hard core programmer probably will prefer to edit java in the src file format cause that works really fast. But a less experienced java developer might choose a point and click editor to compose a functionality that will result in a java class. The java source editing will be much more flexible.
Another way of looking at these domain specific languages (including the programming languages) is from the perspective of structuring software. Object Oriented Programming (OOP) adds structure by grouping methods with their data. Aspect Oriented Programming (AOP) adds a way to extract cross cutting concerns. Dependency Injection (DI) and Inversion of Control (IoC) frameworks adds easy wiring of object graphs. Also graph based execution languages (as covered here) can be helpful to tackle complexity by structuring part of your software project around the execution of a graph.
An intial explanation on Domain Specific Languages (DSL) can be found on Martin Fowler's bliki. But the vision behind it is better elaborated in Martin's article about 'Language Workbenches'.
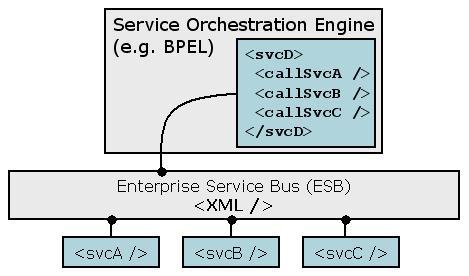
There are numerous graph based process languages. There are big differences in the environment and focus. For instance, BPEL is intended as an XML based service orchestation component on top of an Enterprise Service Bus (ESB) architecture. And a pageflow process language might define how the pages of a webapplication can be navigated. These are two completely different environments.
Despite all these differences, there are two features that you'll find in almost every process language: support for wait states and a graphical represenation. This is no coincidence because it's exactly those two features that are not sufficiently supported in plain Object Oriented (OO) programming languages like Java.
Graph Oriented Programming is a technique to implement these two features in an OO programming language. The dependency of Graph Oriented Programming on OO programming implies that all concrete process languages, implemented on top of Graph Oriented Programming, will have to be developed in OOP. But this does not mean that the process languages themselves expose any of this OOP nature. E.g. BPEL doesn't have any relation to OO programming and it can be implemented on top of Graph Oriented Programming.
An imperative programming language like Java are used to express a sequence of instructions to be executed by one system. There is no wait instruction. An imperative language is perfect for describing e.g. one request response cycle in a server. The system is continuously executing the sequence of instructions till the request is handled and the response is complete.
But one such request is typically part of a bigger scenario. E.g. a client submits a purchase order, this purchase order is to be validated by a purchase order manager. After approval, the information must be entered in the ERP system. Many requests to the server are part of the same bigger scenario.
So process languages are languages to describe the bigger scenario. A very important distinction we must make here is scenarios that are executable on one system (orchestration) and scenarios that describe the protocol between multiple systems (choreography). The Graph Oriented Programming implementation technique is only targets process languages that are executable on one machine (orchestration).
So an orchestration process describes the overall scenario in terms of one system. For example: A process is started when a client submits an order. The next step in the process is the order manager's approval. So the system must add an entry in the task list of the order manager and the wait till the order manager provides the required input. When the input is received, the process continues execution. Now a message is sent to the ERP system and again this system will wait until the response comes back.
So to describe the overall scenario for one system, we need a mechanism to cope with wait states.
In most of the application domains, the execution must be persisted during the wait states. That is why blocking threads is not sufficient. Clever Java programmers might think about the Object.wait() and Object.notify(); methods. Those could be used to simulate wait states but the problem is that threads are not persistable.
Continuations is a technique to make the thread (and the context variables) persistable. This could be a sufficient to solve the wait state problem. But as we will discuss in the next section, also a graphical representation is important for many of the application domains. And continuations is a technique that is based on imperative programming, so it's unsuitable for the graphical representation.
So an important aspect of the support for wait states is that executions need to be persistable. Different application domains might have different requirements for persisting such an execution. For most workflow, BPM and orchestration applications, the execution needs to be persisted in a relational database. Typically, a state transition in the process execution will correspond with one transaction in the database.
Some aspects of software development can benefit very well from a graph based approach. Business Process Management is one of the most obvious application domains of graph based languages. In that example, the communication between a business analyst and the developer is improved using the graph based diagram of the business process as the common language. See also Section 4.5.1, “Business Process Management (BPM)”.
Another aspect that can benefit from a graphical representation is pageflow. In this case, the pages, navigation and action commands are shown and linked together in the graphical representation.
In Graph Oriented Programming we target graph diagrams that represent some form of execution. That is a clear differentiation with for instance UML class diagrams, which represent a static model of the OO data structure.
Also the graphical representation can be seen as a missing feature in OO programming. There is no sensible way in which the execution of an OO program can be represented graphically. So there is no direct relation between an OO program and the graphical view.
In Graph Oriented Programming, the description of the graph is central and it is a real software artifact like e.g. an XML file that describes the process graph. Since the graphical view is an intrinsic part of the software, it is always in sync. There is no need for a manual translation from the graphical requirements into a software design. The software is structured around the graph.
What we present here is an implementation technique for graph based execution languages. The technique presented here is based on runtime interpretation of a graph. Other techniques for graph execution are based on message queues or code generation.
This section will explain the strategy on how graph execution can be implemented on top of an OO programming language. For those who are familiar with design patterns, it's a combination of the command pattern and the chain of responsibility pattern.
We'll start off with the simplest possible model and then extend it bit by bit.
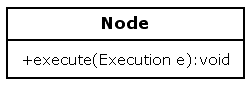
First of all, the structure of the graph is represented with the classes Node and Transition. A transition has a direction so the nodes have leaving- and arriving transitions.
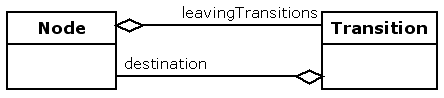
A node is a command and has an execute method. Subclasses of Node are supposed to override the execute method to implement some specific behaviour for that node type.
The execution model that we defined on this graph structure might look similar to finite state machines or UML state diagrams. In fact Graph Oriented Programming can be used to implement those kinds of behaviours, but it also can do much more.
An execution (also known as a token) is represented with a class called Execution. An execution has a reference to the current node.
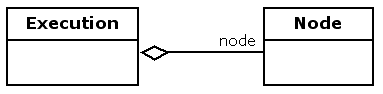
Transitions are able to pass the execution from a source node to a destination node with the method take.
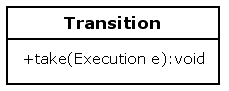
When an execution arrives in a node, that node is executed. The Node's execute method is also responsible for propagating the execution. Propagating the execution means that a node can pass the execution that arrived in the node over one of its leaving transitions to the next node.
When a node's execute method does not propagate the execution, it behaves as a wait state. Also when a new execution is created, it is initialized in some start node and then waits for an event.
An event is given to an execution and it can trigger the execution to start moving. If the event given to an execution relates to a leaving transition of the current node, the execution takes that transition. The execution then will continue to propagate until it enters another node that behaves as a wait state.

So now we can already see that the two main features are supported : wait states and a graphical representation. During wait states, an Execution just points to a node in the graph. Both the process graph and the Execution can be persisted: E.g. to a relational database with an O/R mapper like hibernate or by serializing the object graph to a file. Also you can see that the nodes and transitions form a graph and hence there is a direct coupling with a graphical representation.
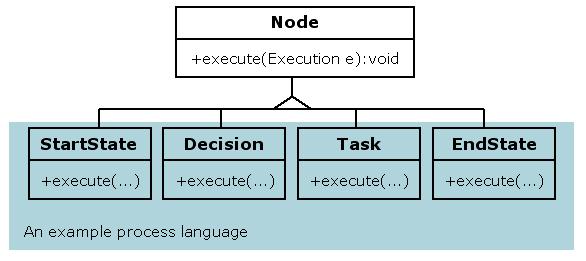
A process language is nothing more then a set of Node-implementations. Each Node-implementation corresponds with a process construct. The exact behaviour of the process construct is implemented by overriding the execute method.
Here we show an example process language with 4 process constructs: a start state, a decision, a task and an end state. This example is unrelated to the jPDL process language.
Concrete node objects can now be used to create process graphs in our example process language.
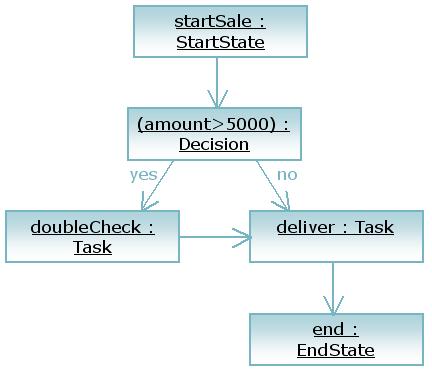
When creating a new execution for this process, we start by positioning the execution in the start node. So as long as the execution does not receive an event, the execution will remain positioned in the start state.
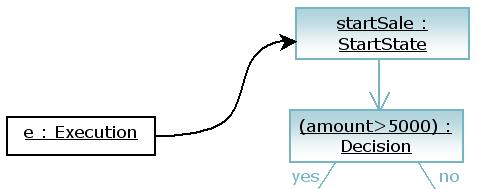
Now let's look at what happens when an event is fired. In this initial situation, we fire the default event that will correspond with the default transition.
That is done by invoking the event method on the execution object. The event method will propagate find the default leaving transition and pass the execution over the transition by invoking the take method on the transition and passing itself in as a parameter.
The transition will pass on the execution to the decision node and invoke the execute method. Let's assume the decision's execute implementation performs a calculation and decides to propagate the execution by sending the 'yes'-event to the execution. That will cause the execution to continue over the 'yes' transition and the execution will arrive in the task 'doubleCheck'.
Let's assume that the execute implementation of the doubleCheck's task node is adds an entry into the checker's task list and then waits for the checker's input by not propagating the execution further.
Now, the execution will remain positioned in the doubleCheck task node. All nested invocations will start to return until the original event method returns.

In some application domains there must be a way to include the execution of programming logic without introducing a node for it. In Business Process Management for example this is a very important aspect. The business analyst is in charge of the graphical representation and the developer is responsible for making it executable. It is not acceptable if the developer must change the graphical diagram to include a technical detail in which the business analyst is not interested.
An Action is also a commands with an execute method. Actions can be associated with events.
There are 2 basic events fired by the Node class while an execution is executing: node-leave and node-enter. Along with the events that cause transitions to be taken this gives already a good freedom of injecting programming logic into the execution of a graph.
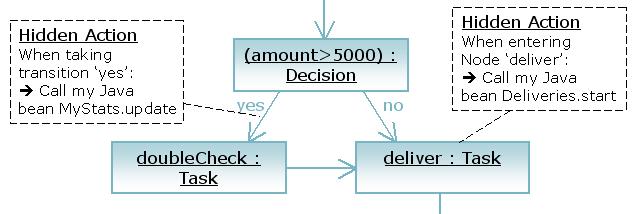
Each event can be associated with a list of actions. All the actions will be executed with the event fires.
In order for people to get acquinted with the principles of Graph Oriented Programming, we have developed these 4 classes in less then 130 lines of code. You can just read the code to get an idea or you can actually start playing with them and implement your own node types.
Here's the example code:
You can also download the whole (297KB) source project and start playing with it yourself. It includes an eclipse project so just importing it in your eclipse as a project should get you going. Also there are a set of tests that show basic process execution and the advanced graph execution concepts covered in the next section.
The previous section introduced the plain Graph Oriented Programming model in its simplest form. This section will discuss various aspects of graph based languages and how Graph Oriented Programming can be used or extended to meet these requirements.
Process variables maintain the contextual data of a process execution. In an insurance claim process, the 'claimed amount', 'approved ammount' and 'isPaid' could be good examples of process variables. In many ways, they are similar to the member fields of a class.
Graph Oriented Programming can be easily extended with support for process variables by associating a set of key-value pairs that are associated with an execution. Concurrent execution paths and process composition will complicate things a bit. Scoping rules will define the visibility of process variables in case of concurrent paths of execution or subprocesses.
'Workflow Data Patterns' is an extensive research report on the types of scoping that can be applied to process variables in the context of subprocessing and concurrent executions.
Suppose that you're developing a 'sale' process with a graph based process language for workflow. After the client submitted the order, there is a sequence of activities for billing the client and there's also a sequence of activities for shipping the items to the client. As you can imagine, the billing activies and shipping activities can be done in parallel.
In that case, one execution will not be sufficient to keep track of the whole process state. Let's go though the steps to extend the Graph Oriented Programming model and add support for concurrent executions.
First, let's rename the execution to an execution path. Then we can introduce a new concept called a process execution. A process execution represents one complete execution of a process and it contains many execution paths.
The execution paths can be ordered hierarchically. Meaning that one root execution path is created when a new process execution is instantiated. When the root execution path is forked into multiple concurrent execution paths, the root is the parent and the newly created execution paths are all children of the root. This way, implementation of a join can become straightforward: the implementation of the join just has to verify if all sibling-execution-paths are already positioned in the join node. If that is the case, the parent execution path can resume execution leaving the join node.
While the hierarchical execution paths and the join implementation based on sibling execution paths covers a large part of the use cases, other concurrency behaviour might be desirable in specific circumstances. For example when multiple merges relate to one split. In such a situation, other combinations of runtime data and merge implementations are required.
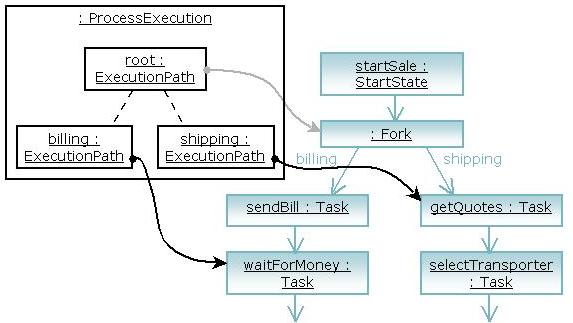
Multiple concurrent paths of execution are often mixed up with multithreaded programming. Especially in the context of workflow and BPM, these are quite different. A process specifies a state machine. Consider for a moment a state machine as being always in a stable state and state transitions are instantanious. Then you can interpret concurrent paths of execution by looking at the events that cause the state transitions. Concurrent execution then means that the events that can be handled are unrelated between the concurrent paths of execution. Now let's assume that state transitions in the process execution relates to a database transition (as explained in Section 4.3.6, “Persistence and Transactions”), then you see that multithreaded programming is actually not even required to support concurrent paths of execution.
Process composition is the ability to include a sub process as part of a super process. This advanced feature makes it possible to add abstraction to process modelling. For the business analyst, this feature is important to handle break down large models in smaller blocks.
The main idea is that the super process has a node in the graph that represents a complete execution of the sub process. When an execution enters the sub-process-node in the super process, several things are to be considered:
- First of all, a new execution is created for the sub process.
- Optionally some of information stored in the process variables of the super process can be injected from the super process execution into the sub process execution. The most easy form is that the sub process node is configured with a set of variables that are just copied from the super process variables to the sub process variables.
- The start-node of the sub process should have only one leaving transition. Process languages that support multiple leaving transitions must have a mechanism to choose one of those transitions based on the process variables of the super process.
- The sub process execution is launched by sending an event that corresponds to the default leaving transition of its start state.
After the sub process entered a wait state, the super process execution will be pointing to the sub-process-node and the sub process execution will be pointing to some wait state.
When the sub process execution finishes, the super process execution can continue. The following aspects need to be considered at that time:
- Process variable information may need to be copied back from the sub process execution into the super process execution.
- The super process execution should continue. Typically, process languages allow only one leaving transition on a sub process node. In that case the super process execution is propagated over that default single leaving transition.
- In case a sub process node is allowed more then one leaving transition, a mechanism has to be introduced to select a leaving transition. This selection can be based on either the sub process execution's variables or the end state of the sub process (a typical state machine can have multiple end states).
TODO: bpel's has an implicit notion of subprocessing, rather then an explicit...
The goal of BPM is to make an organisation run more efficient. The first step is analysing and describing how work gets done in an organisation. Let's define a business process is a description of the way that people and systems work together to get a perticular job done. Once business processes are described, the search for optimisations can begin.
Sometimes business processes have evolved organically and merely looking at the overall business process shows some obvious inefficiencies. Searching for modifications that make a business process more efficient is called Business Process Reengineering (BPR). Once a large part of a business process is automated, statistics and audit trails can help to find and identify these inefficiencies.
Another way to improve efficiency can be to automate whole or parts of the business process using information technology.
Automating and modifying business processes are the most common ways of making an organisation run more efficient.
Managers continiously break down jobs into steps to be executed by their team members. For example a software development manager that organises a team-building event. In that case, the description of the business process might be done only in the head of the manager. Other situations like handling an insurance claim for a large insurance company require a more formal approach to BPM.
The total gain that can be obtained from managing business processes is the efficiency improvements times the number of executions of the process. The cost of managing business processes formally is the extra effort that is spent on analysing, describing, improving and automating the business processes. So that cost has to be taken into consideration when determining which processes will be selected for formal management and/or automation.
orchestration is somtimes supposed to be in the context of service orchestration.
...targetted at less experienced developers.
In my opinion, the current java community is a relatively small community of very hard core power users. Of course, the point and click will have a lot of restrictions cannot handle all of Java's constructs. But it will open up a hole new can of fresh (less-experienced) software developers. So different editors for a single language can target different types/levels of developers.
When the BPM engine can be completely integrated into a software development project and when even the BPM engine's database tables in integrated into the project's database, then we speak of an Embeddable BPM engine. That is the goal we target with Graph Oriented Programming: a common foundation for implementing graph based languages.
Traditionally, the vendors have been searching for the ultimate process language. The approach is to specify a process language as a set of constructs. Each construct has a graphical representation and a runtime behaviour. In other words, each construct is a node type in the process graph. And a process language is just a set of node constructs.
The idea was that the vendors were searching for the best set of process constructs to form a universally applicable process language. This vision is still found a lot today and we call it searching for the ultimate process language.
We believe that the focus should not be on trying to find the ultimate process language, but rather in finding a common foundation that can be used as a basis for process languages in different scenarios and different environment. Graph Oriented Programming as we present it next is to be seen as such a foundation.
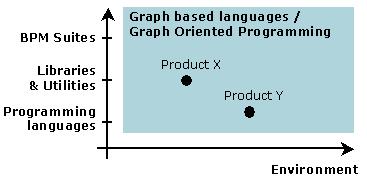
The current landscape of workflow, BPM and orchestration solutions is completely fragmented. In this section we'll describe two dimensions in this fragmentation. The first dimension is called the BPM product continuum and it's shown in the next picture. The term was originally coined by Derek Miers and Paul Harmon in 'The 2005 BPM Suites Report'.
On the left, you can see the programming languages. This side of the continuum is targeted towards the IT developers. Programming languages are the most flexible and it integrates completely with the other software developed for a perticular project. But it takes quite a bit of programming to implement a business process.
On the right, there are the BPM suites. These BPM suites are complete software development environments targetted to be used by business analysts. Software is developed around business processes. No programming has to be done to create executable software in these BPM suites.

Traditional products mark 1 spot in the BPM product continuum. To be complete, these products tend to aim for the far right of the continuum. This is problematic because it results in monolithic system that is very hard to integrate into a project combines plain OOP software with business processes.
Graph Oriented Programming can be built as a simple library that integrates nice with plain programming environment. On the other hand, this library can be packaged and predeployed on a server to become a BPM server. Then other products added and packaged together with the BPM server to become a complete BPM suite.
The net result is that solutions based on Graph Oriented Programming can target the whole continuum. Depending on the requirements in a perticular project, the BPM suite can be peeled and customized to the right level of integration with the software development environment.
The other dimension of fragmentation is the application domain. As show above, a BPM application domain is completely different from service orchestration or pageflow. Also in this dimension, traditional products target one single application domain, where Graph Oriented Programming covers the whole range.
If we set this out in a graph, this gives a clear insight in the current market fragmentation. In the graph based languages market, prices are high and volumes are low. Consolidation is getting started and this technology aims to be a common foundation for what is now a fragmented and confusing market landscape.