
Chapter 7. Process Modelling - JBoss JBPM 3.0.4 userguide 英文版文档
A process definition represents a formal specification of a business process and is based on a directed graph. The graph is composed of nodes and transitions. Every node in the graph is of a specific type. The type of the node defines the runtime behaviour. A process definition has exactly one start state.
A token is one path of execution. A token is the runtime concept that maintains a pointer to a node in the graph.
A process instance is one execution of a process definition. When a process instance is created, a token is created for the main path of execution. This token is called the root token of the process instance and it is positioned in the start state of the process definition.
A signal instructs a token to continue graph execution. When receiving an unnamed signal, the token will leave its current node over the default leaving transition. When a transition-name is specified in the signal, the token will leave its node over the specified transition. A signal given to the process instance is delegated to the root token.
After the token has entered a node, the node is executed. Nodes themselves are responsible for the continuation of the graph execution. Continuation of graph execution is done by making the token leave the node. Each node type can implement a different behaviour for the continuation of the graph execution. A node that does not propagate execution will behave as a state.
Actions are pieces of java code that are executed upon events in the process execution. The graph is an important instrument in the communication about software requirements. But the graph is just one view (projection) of the software being produced. It hides many technical details. Actions are a mechanism to add technical details outside of the graphical representation. Once the graph is put in place, it can be decorated with actions. The main event types are entering a node, leaving a node and taking a transition.
The basis of a process definition is a graph that is made up of nodes and transitions. That information is expressed in an xml file called processdefinition.xml. Each node has a type like e.g. state, decision, fork, join,... Each node has a set of leaving transitions. A name can be given to the transitions that leave a node in order to make them distinct. For example: The following diagram shows a process graph of the jBAY auction process.
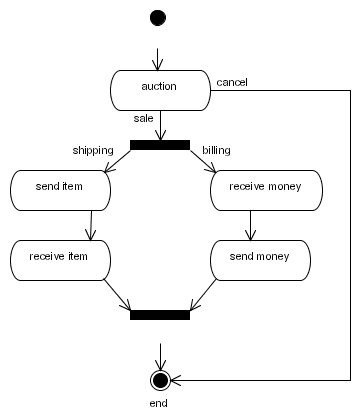
Below is the process graph of the jBAY auction process represented as xml:
<process-definition>
<start-state>
<transition to="auction" />
</start-state>
<state name="auction">
<transition name="auction ends" to="salefork" />
<transition name="cancel" to="end" />
</state>
<fork name="salefork">
<transition name="shipping" to="send item" />
<transition name="billing" to="receive money" />
</fork>
<state name="send item">
<transition to="receive item" />
</state>
<state name="receive item">
<transition to="salejoin" />
</state>
<state name="receive money">
<transition to="send money" />
</state>
<state name="send money">
<transition to="salejoin" />
</state>
<join name="salejoin">
<transition to="end" />
</join>
<end-state name="end" />
</process-definition>A process graph is made up of nodes and transitions. For more information about the graph and its executional model, refer to Chapter 4, Graph Oriented Programming.
Each node has a specific type. The node type determines the what will happen when an execution arrives in the node at runtime. jBPM has a set of preimplemented node types that you can use. Alternatively, you can write custom code for implementing your own specific node behaviour.
Each node has 2 main responsibilities: First, it can execute plain java code. Typically the plain java code relates to the function of the node. E.g. creating a few task instances, sending a notification, updating a database,... Secondly, a node is responsible for propagating the process execution. Basically, each node has the following options for propagating the process execution:
- 1. not propagate the execution. In that case the node behaves as a wait state.
- 2. propagate the execution over one of the leaving transitions of the node. This means that the token that originally arrived in the node is passed over one of the leaving transitions with the API call executionContext.leaveNode(String). The node will now act as an automatic node in the sense it can execute some custom programming logic and then continue process execution automatically without waiting.
- 3. create new paths of execution. a node can decide to create new tokens. Each new token represents a new path of execution and each new token can be launched over the node's leaving transitions. A good example of this kind of behaviour is the fork node.
- 4. end paths of execution. A node can decide to end a path of execution. That means that the token is ended and the path of execution is finished.
- 5. more general, a node can modify the whole runtime structure of the process instance. The runtime structure is a process instance that contains a tree of tokens. Each token represents a path of execution. A node can create and end tokens, put each token in a node of the graph and launch tokens over transitions.
jBPM contains --as any workflow and BPM engine-- a set of preimplemented node types that have a specific documented configuration and behaviour. But the unique thing about jBPM and the Graph Oriented Programming foundation is that we open up the model for developers. Developers can write their own node behaviour very easy and use it in a process.
That is where traditional workflow and BPM systems are much more closed. They usually supply a fixed set of node types (called the process language). Their process language is closed and the executional model is hidden in the runtime environment. Research of workflow patterns has shown that any process language is not powerfull enough. We have decided for a simple model and allow developers to write their own node types. That way the JPDL process language is open ended.
Next, we discuss the most important node types of JPDL.
A task node represents one or more tasks that are to be performed by humans. So when execution arrives in a task node, task instances will be created in the task lists of the workflow participants. After that, the node will behave as a wait state. So when the users perform their task, the task completion will trigger the resuming of the execution. In other words, that leads to a new signal being called on the token.
A state is a bare-bones wait state. The difference with a task node is that no task instances will be created in any task list. This can be usefull if the process should wait for an external system. E.g. upon entry of the node (via an action on the node-enter event), a message could be sent to the external system. After that, the process will go into a wait state. When the external system send a response message, this can lead to a token.signal(), which triggers resuming of the process execution.
Actually there are 2 ways to model a decision. The distinction between the two is based on *who* is making the decision. Should the decision made by the process (read: specified in the process definition). Or should an external entity provide the result of the decision.
When the decision is to be taken by the process, a decision node should be used. There are basically 2 ways to specify the decision criteria. Simplest is by adding condition elements on the transitions. Conditions are beanshell script expressions that return a boolean. At runtime the decision node will loop over its leaving transitions (in the order as specified in the xml), and evaluate each condition. The first transition for which the conditions resolves to 'true' will be taken. Alternatively, an implementation of the DecisionHandler can be specified. Then the decision is calculated in a java class and the selected leaving transition is returned by the decide-method of the DecisionHandler implementation.
When the decision is taken by an external party (meaning: not part of the process definition), you should use multiple transitions leaving a state or wait state node. Then the leaving transition can be provided in the external trigger that resumes execution after the wait state is finished. E.g. Token.signal(String transitionName) and TaskInstance.end(String transitionName).
A fork splits one path of execution into multiple concurrent paths of execution. The default fork behaviour is to create a child token for each transition that leaves the fork, creating a parent-child relation between the token that arrives in the fork.
The default join assumes that all tokens that arrive in the join are children of the same parent. This situation is created when using the fork as mentioned above and when all tokens created by a fork arrive in the same join. A join will end every token that enters the join. Then the join will examine the parent-child relation of the token that enters the join. When all sibling tokens have arrived in the join, the parent token will be propagated over the (unique!) leaving transition. When there are still sibling tokens active, the join will behave as a wait state.
The type node serves the situation where you want to write your own code in a node. The nodetype node expects one subelement action. The action is executed when the execution arrives in the node. The code you write in the actionhandler can do anything you want but it is also responsible for propagating the execution.
This node can be used if you want to use a JavaAPI to implement some functional logic that is important for the business analyst. By using a node, the node is visible in the graphical representation of the process. For comparison, actions --covered next-- will allow you to add code that is invisible in the graphical representation of the process, in case that logic is not important for the business analyst.
Actions are pieces of java code that are executed upon events in the process execution. The graph is an important instrument in the communication about software requirements. But the graph is just one view (projection) of the software being produced. It hides many technical details. Actions are a mechanism to add technical details outside of the graphical representation. Once the graph is put in place, it can be decorated with actions. This means that java code can be associated with the graph without changing the structure of the graph. The main event types are entering a node, leaving a node and taking a transition.
Note the difference between an action that is placed in an event versus an action that is placed in a node. Actions that are put in an event are executed when the event fires. Actions on events have no way to influence the flow of control of the process. It is similar to the observer pattern. On the other hand, an action that is put on a node has the responsibility of propagating the execution.
Let's look at an example of an action on an event. Suppose we want to do a database update on a given transition. The database update is technically vital but it is not important to the business analyst.
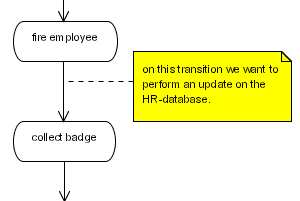
public class RemoveEmployeeUpdate implements ActionHandler {
public void execute(ExecutionContext ctx) throws Exception {
// get the fired employee from the process variables.
String firedEmployee = (String) ctx.getContextInstance().getVariable("fired employee");
// by taking the same database connection as used for the jbpm updates, we
// reuse the jbpm transaction for our database update.
Connection connection = ctx.getProcessInstance().getJbpmSession().getSession().getConnection();
Statement statement = connection.createStatement("DELETE FROM EMPLOYEE WHERE ...");
statement.execute();
statement.close();
}
}<process-definition name="yearly evaluation">
...
<state name="fire employee">
<transition to="collect badge">
<action class="com.nomercy.hr.RemoveEmployeeUpdate" />
</transition>
</state>
<state name="collect badge">
...
</process-definition>For more information about adding configurations to your custom actions and how to specify the configuration in the processdefinition.xml, see Section 13.2.3, “Configuration of delegations”
Actions can be given a name. Named actions can be referenced from other locations where actions can be specified. Named actions can also be put as child elements in the process definition.
This feature is interesting if you want to limit duplication of action configurations (e.g. when the action has complicated configurations). Another use case is execution or scheduling of runtime actions.
Events specify moments in the execution of the process. The jBPM engine will fire events during graph execution. This occurs when jbpm calculats the next state (read: processing a signal). An event is always relative to an element in the process definition like e.g. the process definition, a node or a transition. Most process elements can fire different types of events. A node for example can fire a node-enter event and a node-leave event. Events are the hooks for actions. Each event has a list of actions. When the jBPM engine fires an event, the list of actions is executed.
Superstates create a parent-child relation in the elements of a process definition. Nodes and transitions contained in a superstate have that superstate as a parent. Top level elements have the process definition as a parent. The process definition does not have a parent. When an event is fired, the event will be propagated up the parent hierarchy. This allows e.g. to capture all transition events in a process and associate actions with these events in a centralized location.
A script is an action that executes a beanshell script. For more information about beanshell, see the beanshell website. By default, all process variables are available as script-variables and no script-variables will be written to the process variables. Also the following script-variables will be available :
- executionContext
- token
- node
- task
- taskInstance
<process-definition>
<event type="node-enter">
<script>
System.out.println("this script is entering node "+node);
</script>
</event>
...
</process-definition>To customize the default behaviour of loading and storing variables into the script, the variable element can be used as a sub-element of script. In that case, the script expression also has to be put in a subelement of script: expression.
<process-definition>
<event type="process-end">
<script>
<expression>
a = b + c;
</expression>
<variable name='XXX' access='write' mapped-name='a' />
<variable name='YYY' access='read' mapped-name='b' />
<variable name='ZZZ' access='read' mapped-name='c' />
</script>
</event>
...
</process-definition>Before the script starts, the process variables YYY and ZZZ will be made available to the script as script-variables b and c respectively. After the script is finished, the value of script-variable a is stored into the process variable XXX.
If the access attribute of variable contains 'read', the process variable will be loaded as a script-variable before script evaluation. If the access attribute contains 'write', the script-variable will be stored as a process variable after evaluation. The attribute mapped-name can make the process variable available under another name in the script. This can be handy when your process variable names contain spaces or other invalid script-literal-characters.
Note that it's possible to fire your own custom events at will during the execution of a process. Events are uniquely defined by the combination of a graph element (nodes, transitions, process definitions and superstates are graph elements). In actions, in your own custom node implementations, or even outside the execution of a process instance, you can call the GraphElement.fireEvent(String eventType, ExecutionContext executionContext);. The names of the event types can be chosen freely.
A Superstate is a group of nodes. Superstates can be nested recursively. Superstates can be used to bring some hierarchy in the process definition. For example, one application could be to group all the nodes of a process in phases. Actions can be associated with superstate events. A consequence is that a token can be in multiple nested nodes at a given time. This can be convenient to check wether a process execution is e.g. in the start-up phase. In the jBPM model, you are free to group any set of nodes in a superstate.
All transitions leaving a superstate can be taken by tokens in nodes contained within the super state. Transitions can also arrive in superstates. In that case, the token will be redirected to the first node in the superstate. Nodes from outside the superstate can have transitions directly to nodes inside the superstate. Also, the other way round, nodes within superstates can have transitions to nodes outside the superstate or to the superstate itself. Superstates also can have self references.
There are 2 events unique to superstates: superstate-enter and superstate-leave. These events will be fired no matter over which transitions the node is entered or left respectively. As long as a token takes transitions within the superstate, these events are not fired.
Note that we have created separate event types for states and superstates. This is to make it easy to distinct between superstate events and node events that are propagated from within the superstate.
Node names have to be unique in their scope. The scope of the node is its node-collection. Both the process definintion and the superstate are node collections. To refer to nodes in superstates, you have to specify the relative, slash (/) separated name. The slash separates the node names. Use '..' to refer to an upper level. The next example shows how to reference a neighbouring superstate:
<process-definition>
...
<state name="preparation">
<transition to="phase one/invite murphy"/>
</state>
<super-state name="phase one">
</super-state>
...
</process-definition>The next example will show how to go up the superstate hierarchy
<process-definition>
...
<super-state name="phase one">
<state name="preparation">
<transition to="../phase two/invite murphy"/>
</node>
</super-state>
<super-state name="phase two">
</super-state>
...
</process-definition>The exception handling mechanism of jBPM only applies to java exceptions. Graph execution on itself cannot result in problems. It is only the execution of delegation classes that can lead to exceptions.
On process-definitions, nodes and transitions, a list of exception-handlers can be specified. Each exception-handler has a list of actions. When an exception occurs in a delegation class, the process element parent hierarchy is serached for an appropriate exception-handler. When it is found, the actions of the exception-handler are executed.
Note that the exception handling mechanism of jBPM is not completely similar to the java exception handling. In java, a caught exception can have an influence on the control flow. In the case of jBPM, control flow cannot be changed by the jBPM exception handling mechanism. The exception is either caught or uncaught. Uncaught exceptions are thrown to the client (e.g. the client that called the token.signal()) or the exception is caught by a jBPM exception-handler. For caught exceptions, the graph execution continues as if no exception has occurred.
Note that in an action that handles an exception, it is possible to put the token in an arbitrary node in the graph with Token.setNode(Node node).
Process composition is supported in jBPM by means of the process-state. The process state is a state that is associated with another process definition. When graph execution arrives in the process state, a new process instance of the sub-process is created and it is associated with the path of execution that arrived in the process state. The path of execution of the super process will wait till the sub process instance has ended. When the sub process instance ends, the path of execution of the super process will leave the process state and continue graph execution in the super process.
<process-definition name="hire">
<start-state>
<transition to="initial interview" />
</start-state>
<process-state name="initial interview">
<sub-process name="interview" />
<variable name="a" access="read,write" mapped-name="aa" />
<variable name="b" access="read" mapped-name="bb" />
<transition to="..." />
</process-state>
...
</process-definition>This 'hire' process contains a process-state that spawns an 'interview' process. When execution arrives in the 'first interview', a new execution (=process instance) for the latest version of the 'interview' process is created. Then variable 'a' from the hire process is copied into variable 'aa' from the interview process. The same way, hire variable 'b' is copied into interview variable 'bb'. When the interview process finishes, only variable 'aa' from the interview process is copied back into the 'a' variable of the hire process.
In general, When a subprocess is started, all variables with read access are read from the super process and fed into the newly created sub process before the signal is given to leave the start state. When the sub process instances is finished, all the variables with write access will be copied from the sub process to the super process. The mapped-name attribute of the variable element allows you to specify the variable name that should be used in the sub process.
In jBPM, it's quite easy to write your own custom nodes. For creating custom nodes, an implementation of the ActionHandler has to be written. The implementation can execute any business logic, but also has the responsibility to propagate the graph execution. Let's look at an example that will update an ERP-system. We'll read an amout from the ERP-system, add an amount that is stored in the process variables and store the result back in the ERP-system. Based on the size of the amount, we have to leave the node via the 'small amounts' or the 'large amounts' transition.
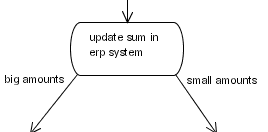
public class AmountUpdate implements ActionHandler {
public void execute(ExecutionContext ctx) throws Exception {
// business logic
Float erpAmount = ...get amount from erp-system...;
Float processAmount = (Float) ctx.getContextInstance().getVariable("amount");
float result = erpAmount.floatValue() + processAmount.floatValue();
...update erp-system with the result...;
// graph execution propagation
if (result > 5000) {
ctx.leaveNode(ctx, "big amounts");
} else {
ctx.leaveNode(ctx, "small amounts");
}
}
}It is also possible to create and join tokens in custom node implementations. For an example on how to do this, check out the Fork and Join node implementation in the jbpm source code :-).
The graph execution model of jBPM is based on interpretation of the process definition and the chain of command pattern.
Interpretation of the process definition means that the process definition data is stored in the database. At runtime the process definition information is used during process execution. Note for the concerned : we use hibernate's second level cache to avoid loading of definition information at runtime. Since the process definitions don't change (see process versioning) hibernate can cache the process definitions in memory.
The chain of command pattern means that each node in the graph is responsible for propagating the process execution. If a node does not propagate execution, it behaves as a wait state.
The idea is to start execution on process instances and that the execution continues till it enters a wait state.
A token represents a path of execution. A token has a pointer to a node in the process graph. During waitstates, the tokens can be persisted in the database. Now we are going to look at the algorithm for calculating the execution of a token. Execution starts when a signal is sent to a token. The execution is then passed over the transitions and nodes via the chain of command pattern. These are the relevant methods in a class diagram.
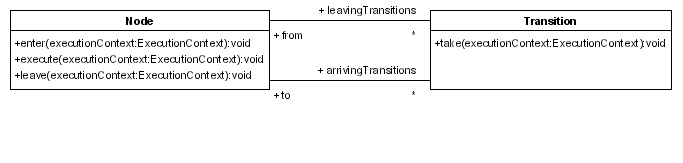
When a token is in a node, signals can be sent to the token. Sending a signal is an instruction to start execution. A signal must therefore specify a leaving transition of the token's current node. The first transition is the default. In a signal to a token, the token takes its current node and calls the Node.leave(ExecutionContext,Transition) method. Think of the ExecutionContext as a Token because the main object in an ExecutionContext is a Token. The Node.leave(ExecutionContext,Transition) method will fire the node-leave event and call the Transition.take(ExecutionContext). That method will fire the transition event and call the Node.enter(ExecutionContext) on the destination node of the transition. That method will fire the node-enter event and call the Node.execute(ExecutionContext). Each type of node has its own behaviour that is implementated in the execute method. Each node is responsible for propagating graph execution by calling the Node.leave(ExecutionContext,Transition) again. In summary:
- Token.signal(Transition)
- --> Node.leave(ExecutionContext,Transition)
- --> Transition.take(ExecutionContext)
- --> Node.enter(ExecutionContext)
- --> Node.execute(ExecutionContext)
Note that the complete calculation of the next state, including the invocation of the actions is done in the thread of the client. A common misconception is that all calculations *must* be done in the thread of the client. As with any asynchronous invocation, you can use asynchronous messaging (JMS) for that. When the message is sent in the same transaction as the process instance update, all synchronization issues are taken care of. Some workflow systems use asynchronous messaging between all nodes in the graph. But in high throughput environments, this algorithm gives much more control and flexibility for tweaking performance of a business process.