
Chapter 6. Persistence - JBoss JBPM 3.0.4 userguide 英文版文档
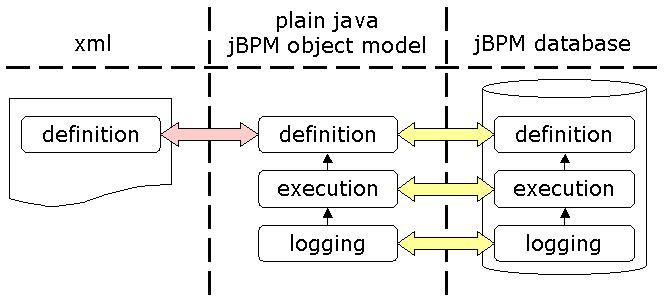
A process definition can be represented in 3 different forms : as xml, as java objects and as records in the jBPM database. Executional (=runtime) information and logging information can be represented in 2 forms : as java objects and as records in the jBPM database.
For more information about the xml representation of process definitions and process archives, see Chapter 13, jBPM Process Definition Language (JPDL).
This chapter will discuss the transformations done between the java objects and the jBPM database. To store java objects in the database and retrieve them, jBPM uses hibernate internally. While it is not strictly necessary to have hibernate knowledge for using jBPM, it is recommended.
More information on how to deploy a process archive to the database can be found in Section 13.1.1, “Deploying a process archive”
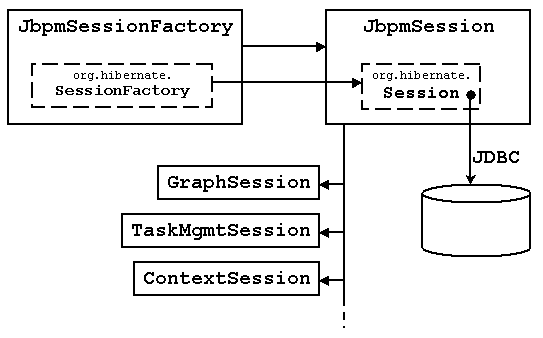
The jBPM persistence operations can be found in the named sessions like e.g. GraphSession, TaskMgmtSession and ContextSession,... The named sessions can be obtained from a JbpmSession. The JbpmSession in its turn can be obtained from a JbpmSessionFactory.
A JbpmSessionFactory is threadsafe so in your application, you need one JbpmSessionFactory. That singleton can be referenced e.g. in a static variable with lazy initialization (beware about the issues around lazy initialization and double-checked locking). At creation time, the JbpmSessionFactory prepares all information in a way that JbpmSessions can be created super fast.
As a user, you should create one JbpmSession per thread or per request. The JbpmSession has a JDBC connection to the database.
The purpose of the JbpmSession and JbpmSessionFactory is only to wrap their hibernate counterparts. For advanced features such as detached objects or optimistic locking, see the hibernate documentation.
public class PersistenceApiTest extends TestCase {
static JbpmSessionFactory jbpmSessionFactory = JbpmSessionFactory.buildJbpmSessionFactory();
public void testStartProcessInstance() {
// obtain a session
JbpmSession jbpmSession = jbpmSessionFactory.openJbpmSession();
try {
// start a user managed transaction
jbpmSession.beginTransaction();
// load information from the database
// (note that process definitions will be cached in memory
// in the second level cache of hibernate)
ProcessDefinition auctionProcess =
jbpmSession.getGraphSession().findLatestProcessDefinition("auction");
// perform a POJO workflow operation on the plain object model.
ProcessInstance auctionInstance = new ProcessInstance(auctionProcess);
auctionInstance.signal();
// store the result in the database
jbpmSession.getGraphSession().saveProcessInstance(auctionInstance);
// commit the user transaction
jbpmSession.commitTransaction();
} finally {
// close the session.
jbpmSession.close();
}
}
}The easiest way to configure the hibernate SessionFactory is by putting a file called hibernate.cfg.xml in the root of the classpath. The file hibernate.cfg.xml contains the information on how to obtain jdbc connections and also the location of the hibernate mapping files. You'll find an example of such a mapping file in directory test/java.
More details on how to configure hibernate can be found in the hibernate reference manual, section session configuration.
The basic approach of jBPM is to leverage the hibernate capabilities for demarcation of transactions. The two most common scenarios are explained here:
For user transaction management, the JbpmSession has methods
- JbpmSession.beginTransaction()
- JbpmSession.commitTransaction()
- JbpmSession.rollbackTransaction()
The behaviour of these methods depends on the hibernate configuration.
If you have configured hibernate to manage its own JDBC connections (e.g. with a C3P0 connection pool), the transaction operations will result in the corresponding operations on the JDBC connection. This configuration requires you to specify the JDBC connection properties in the hibernate configuration (hibernate.cfg.xml). Optionally, you can configure connection pooling by specifying the c3p0 connection pooling properties.
When you have configured hibernate for obtaining connections from a DataSource in an application server, the transaction methods will call the corresponding methods on the UserTransaction object in the container.
More details on how to configure the transactions can be found in the hibernate reference manual, section transaction strategy.
The jBPM database contains the process definitions, the process executions and the logging data. Process definitions data is static and does not change (see Section 13.1.2, “Process versioning”. Process executions reference data in the process definitions. And the process logs contain information about the all the changes in the process executions.
jBPM uses hibernate 3.0 as its O/R mapper. This means that hibernate is responsible for the conversions between the jBPM java objects and the persistent representation of these objects in a relational database. Note that you don't have to know hibernate to get started with jBPM. Hibernate is used internally in jBPM. But understanding the basics of hibernate, will help you to understand the finer semantics of the jBPM API.
Let's look at a few examples to get an idea about the hibernate functionality :
- deploying a process archive: deploying a process archive is done in several steps, in the first step, the archive is parsed and a java object model is created for it. That object graph will be handed over to hibernate. Hibernate will then issue the necessary SQL insert statements to the relational database.
- updating a process instance: another function of hibernate it dirty checking. This means that hibernate will calculate the difference between 2 object graphs and issue the necessary SQL update statements (and inserts and deletes) to the database to bring the database data in sync with the java object. So when you want to continue execution of a process instance, you use the ProcessInstance JbpmSession.getGraphSession().loadProcessInstance(Long pid), jBPM will delegate this call to hibernate. Hibernate will load the data of the process instance from the database and construct the jBPM java objects from it. After that you are free to modify the process instance java objects just like any other java objects. When you're done (e.g. after the execution entered a wait state again) you can store the modified process instance in the database with JbpmSession.getGraphSession().saveProcessInstance(ProcessInstance processInstance). jBPM will again delegate this task to hibernate and hibernate will calculate the the differences between the given processInstance and the processInstance that was originally loaded from the database. This is called dirty checking. Hibernate will then calculate all the differences and issue the necessary SQL statements to bring the database in sync with the java object.
To perform its task, hibernate needs a set of mapping files and configuration properties. The mapping files describe how the java objects are mapped onto the relational database schema. jBPM includes the mapping files for all the jBPM domain classes.
The main information in the configuration properties of hibernate describe the database connection. This includes the jdbc connection properties and the database dialect. The SQL dialect is used for an important feature of hibernate : database independence. Each type of database has roughly the same SQL, but there are some minor differences between the SQL syntax of the different databases. Hibernate knows about these differences through the dialect property and can create the proper SQL for any type of database. See the hibernate docs for a full list of supported databases.
The hypersonic database is an ideal database for developing java software that involves a relational database. Especially the hypersonic in-memory mode is very convenient for writing unit tests that include database operation. The hypersonic in-memory database keeps all its data in memory and doesn't store it on disk. The unit tests of jBPM will start from an empty in-memory database. Then the hibernate schema generation tool is used to create the jBPM tables. We provide the hibernate mapping files for the jBPM classes as input for the hibernate schema generator. Then the hibernate schema generation calculates the database schema (DDL) from that information. These DDL statements are then executed on the hypersonic in-memory database and this creates a fresh, empty jBPM database.
Support for other databases besides the hypersonic in-memory database is provided in a separate jbpm database extension package : jbpm-<version>-db.zip. See Section 2.1, “Downloadables Overview” for download instructions. This package contains the ant scripts to test jBPM against that particular database and to generate database DDL scripts for that SQL dialect (create, drop and clean) for each supported database.
After unzipping the file jbpm-<version>-db.zip, update the build.properties and set the property jbpm.3.location to the home directory of your jbpm-<version> (relative or absolute)
The database extension pack contains an ant build script (build.xml) in its root directory. This script contains targets to create scripts for the supported databases and scripts for testing jBPM against the databases. Run ant -p to get more information on the build targets. The readme.html file in the database extension pack contains further detailed information about the different database systems implemented and their status.
The scripts that are generated are default scripts. For customizations and optimizations for your specific usage, you should ask your DBA to review the database scripts. Common customizations include addition of indexes e.g. on the ACTORID_ field of the JBPM_TASKINSTANCE table and updates of the maximum text lengths of the columns.
If your database is not supported, you can quite easily copy the approach that we have taken and test jBPM against your database. We are eager to include support for all databases, so let us know the following information when you test with your database:
- the jbpm.test.hibernate.properties configuration
- where to download the database driver and the version
- database version that you used
- any issues or failing tests that you encounter