
String (Java 2 Platform SE 5.0) - JavaTM 2 Platform Standard Edition 5.0 API ЙцЗЖжаЮФАц
|
JavaTM 2 Platform Standard Ed. 5.0 |
|||||||||
| ЩЯвЛИіРр ЯТвЛИіРр | ПђМм ЮоПђМм | |||||||||
| еЊвЊЃК ЧЖЬз | зжЖЮ | ЙЙдьЗНЗЈ | ЗНЗЈ | ЯъЯИаХЯЂЃК зжЖЮ | ЙЙдьЗНЗЈ | ЗНЗЈ | |||||||||
java.lang
Рр String
java.lang.Objectjava.lang.String
- ЫљгавбЪЕЯжЕФНгПкЃК
- Serializable, CharSequence, Comparable<String>
public final class String
- extends Object
- implements Serializable, Comparable<String>, CharSequence
- extends Object
String РрДњБэзжЗћДЎЁЃJava ГЬађжаЕФЫљгазжЗћДЎзжУцжЕЃЈШч "abc" ЃЉЖМзїЮЊДЫРрЕФЪЕР§РДЪЕЯжЁЃ
зжЗћДЎЪЧГЃСПЃЛЫќУЧЕФжЕдкДДНЈжЎКѓВЛФмИФБфЁЃзжЗћДЎЛКГхЧјжЇГжПЩБфЕФзжЗћДЎЁЃвђЮЊ String ЖдЯѓЪЧВЛПЩБфЕФЃЌЫљвдПЩвдЙВЯэЫќУЧЁЃР§ШчЃК
String str = "abc";
ЕШаЇгкЃК
char data[] = {'a', 'b', 'c'};
String str = new String(data);
ЯТУцИјГіСЫвЛаЉШчКЮЪЙгУзжЗћДЎЕФИќЖрР§згЃК
System.out.println("abc");
String cde = "cde";
System.out.println("abc" + cde);
String c = "abc".substring(2,3);
String d = cde.substring(1, 2);
String РрАќРЈЕФЗНЗЈгаЃКМьВщађСаЕФЕЅИізжЗћЃЛБШНЯзжЗћДЎЃЛЫбЫїзжЗћДЎЃЛЬсШЁзгзжЗћДЎЃЛДДНЈзжЗћДЎИББОЃЌдкИУИББОжаЃЌЫљгаЕФзжЗћЖМБЛзЊЛЛЮЊДѓаДЛђаЁаДаЮЪНЁЃДѓаЁаДгГЩфЛљгк Character РржИЖЈЕФ Unicode Standard АцБОЁЃ
Java гябдЬсЙЉЖдзжЗћДЎДЎСЊЗћКХЃЈ"+"ЃЉКЭЦфЫћЖдЯѓЕНзжЗћДЎЕФзЊЛЛЕФЬиЪтжЇГжЁЃзжЗћДЎДЎСЊЪЧЭЈЙ§ StringBuilderЃЈЛђ StringBufferЃЉРрМАЦф append ЗНЗЈЪЕЯжЕФЁЃзжЗћДЎзЊЛЛЪЧЭЈЙ§ toString ЗНЗЈЪЕЯжЕФЃЌИУЗНЗЈгЩ Object РрЖЈвхЃЌВЂПЩБЛ Java жаЫљгаРрМЬГаЁЃгаЙизжЗћДЎДЎСЊКЭзЊЛЛЕФИќЖраХЯЂЃЌЧыВЮдФ GoslingЁЂJoy КЭ Steele КЯжјЕФЁЖThe Java Language SpecificationЁЗЁЃ
Г§ЗЧСэааЫЕУїЃЌЗёдђНЋ null ВЮЪ§ДЋЕнИјДЫРржаЕФЙЙдьЗНЗЈЛђЗНЗЈЖМЛсХзГі NullPointerExceptionЁЃ
String БэЪОвЛИі UTF-16 ИёЪНЕФзжЗћДЎЃЌЦфжаЕФдіВЙзжЗћ гЩДњРэЯюЖд БэЪОЃЈгаЙиЯъЯИаХЯЂЃЌЧыВЮдФ Character РржаЕФ Unicode зжЗћБэЪОаЮЪНЃЉЁЃЫїв§жЕЪЧжИ char ДњТыЕЅдЊЃЌвђДЫдіВЙзжЗћдк String жаеМгУСНИіЮЛжУЁЃ
String РрЬсЙЉДІРэ Unicode ДњТыЕуЃЈМДзжЗћЃЉКЭ Unicode ДњТыЕЅдЊЃЈМД char жЕЃЉЕФЗНЗЈЁЃ
- ДгвдЯТАцБОПЊЪМЃК
- JDK1.0
- СэЧыВЮМћЃК
Object.toString(),StringBuffer,StringBuilder,Charset, ађСаЛЏБэИё
| зжЖЮеЊвЊ | |
|---|---|
static Comparator<String> |
CASE_INSENSITIVE_ORDER
вЛИіХХађ String ЖдЯѓЕФ ComparatorЃЌЫќЕФзїгУгы compareToIgnoreCase ЯрЭЌЁЃ |
| ЙЙдьЗНЗЈеЊвЊ | |
|---|---|
String()
ГѕЪМЛЏвЛИіаТДДНЈЕФ String ЖдЯѓЃЌЫќБэЪОвЛИіПезжЗћађСаЁЃ |
|
String(byte[] bytes)
ЙЙдьвЛИіаТЕФ StringЃЌЗНЗЈЪЧЪЙгУЦНЬЈЕФФЌШЯзжЗћМЏНтТызжНкЕФжИЖЈЪ§зщЁЃ |
|
String(byte[] ascii,
int hibyte)
вбЙ§ЪБЁЃ ИУЗНЗЈЮоЗЈНЋзжНке§ШЗзЊЛЛЮЊзжЗћЁЃДг JDK 1.1 Ц№ЃЌЭъГЩИУзЊЛЛЕФЪзбЁЗНЗЈЪЧЭЈЙ§ String ЙЙдьЗНЗЈЃЌИУЗНЗЈНгЪмвЛИізжЗћМЏУћГЦЛђЪЙгУЦНЬЈЕФФЌШЯзжЗћМЏЁЃ |
|
String(byte[] bytes,
int offset,
int length)
ЙЙдьвЛИіаТЕФ StringЃЌЗНЗЈЪЧЪЙгУжИЖЈЕФзжЗћМЏНтТызжНкЕФжИЖЈзгЪ§зщЁЃ |
|
String(byte[] ascii,
int hibyte,
int offset,
int count)
вбЙ§ЪБЁЃ ИУЗНЗЈЮоЗЈНЋзжНке§ШЗзЊЛЛЮЊзжЗћЁЃДг JDK 1.1 ПЊЪМЃЌЭъГЩИУзЊЛЛЕФЪзбЁЗНЗЈЪЧЭЈЙ§ String ЙЙдьЗНЗЈЃЌЫќНгЪмвЛИізжЗћМЏУћГЦЃЌЛђепЪЙгУЦНЬЈФЌШЯЕФзжЗћМЏЁЃ |
|
String(byte[] bytes,
int offset,
int length,
String charsetName)
ЙЙдьвЛИіаТЕФ StringЃЌЗНЗЈЪЧЪЙгУжИЖЈЕФзжЗћМЏНтТызжНкЕФжИЖЈзгЪ§зщЁЃ |
|
String(byte[] bytes,
String charsetName)
ЙЙдьвЛИіаТЕФ StringЃЌЗНЗЈЪЧЪЙгУжИЖЈЕФзжЗћМЏНтТыжИЖЈЕФзжНкЪ§зщЁЃ |
|
String(char[] value)
ЗжХфвЛИіаТЕФ StringЃЌЫќБэЪОЕБЧАзжЗћЪ§зщВЮЪ§жаАќКЌЕФзжЗћађСаЁЃ |
|
String(char[] value,
int offset,
int count)
ЗжХфвЛИіаТЕФ StringЃЌЫќАќКЌРДздИУзжЗћЪ§зщВЮЪ§ЕФвЛИізгЪ§зщЕФзжЗћЁЃ |
|
String(int[] codePoints,
int offset,
int count)
ЗжХфвЛИіаТЕФ StringЃЌЫќАќКЌИУ Unicode ДњТыЕуЪ§зщВЮЪ§ЕФвЛИізгЪ§зщЕФзжЗћЁЃ |
|
String(String original)
ГѕЪМЛЏвЛИіаТДДНЈЕФ String ЖдЯѓЃЌБэЪОвЛИігыИУВЮЪ§ЯрЭЌЕФзжЗћађСаЃЛЛЛОфЛАЫЕЃЌаТДДНЈЕФзжЗћДЎЪЧИУВЮЪ§зжЗћДЎЕФвЛИіИББОЁЃ |
|
String(StringBuffer buffer)
ЗжХфвЛИіаТЕФзжЗћДЎЃЌЫќАќКЌЕБЧААќКЌдкзжЗћДЎЛКГхЧјВЮЪ§жаЕФзжЗћађСаЁЃ |
|
String(StringBuilder builder)
ЗжХфвЛИіаТЕФзжЗћДЎЃЌЫќАќКЌЕБЧААќКЌдкзжЗћДЎЩњГЩЦїВЮЪ§жаЕФзжЗћађСаЁЃ |
|
| ЗНЗЈеЊвЊ | |
|---|---|
char |
charAt(int index)
ЗЕЛижИЖЈЫїв§ДІЕФ char жЕЁЃ |
int |
codePointAt(int index)
ЗЕЛижИЖЈЫїв§ДІЕФзжЗћЃЈUnicode ДњТыЕуЃЉЁЃ |
int |
codePointBefore(int index)
ЗЕЛижИЖЈЫїв§жЎЧАЕФзжЗћЃЈUnicode ДњТыЕуЃЉЁЃ |
int |
codePointCount(int beginIndex,
int endIndex)
ЗЕЛиДЫ String ЕФжИЖЈЮФБОЗЖЮЇжаЕФ Unicode ДњТыЕуЪ§ЁЃ |
int |
compareTo(String anotherString)
АДзжЕфЫГађБШНЯСНИізжЗћДЎЁЃ |
int |
compareToIgnoreCase(String str)
ВЛПМТЧДѓаЁаДЃЌАДзжЕфЫГађБШНЯСНИізжЗћДЎЁЃ |
String |
concat(String str)
НЋжИЖЈзжЗћДЎСЊЕНДЫзжЗћДЎЕФНсЮВЁЃ |
boolean |
contains(CharSequence s)
ЕБЧвНіЕБДЫзжЗћДЎАќКЌ char жЕЕФжИЖЈађСаЪБЃЌВХЗЕЛи trueЁЃ |
boolean |
contentEquals(CharSequence cs)
ЕБЧвНіЕБДЫ String БэЪОгыжИЖЈађСаЯрЭЌЕФ char жЕЪБЃЌВХЗЕЛи trueЁЃ |
boolean |
contentEquals(StringBuffer sb)
ЕБЧвНіЕБДЫ String БэЪОгыжИЖЈЕФ StringBuffer ЯрЭЌЕФзжЗћађСаЪБЃЌВХЗЕЛи trueЁЃ |
static String |
copyValueOf(char[] data)
ЗЕЛижИЖЈЪ§зщжаБэЪОИУзжЗћађСаЕФзжЗћДЎЁЃ |
static String |
copyValueOf(char[] data,
int offset,
int count)
ЗЕЛижИЖЈЪ§зщжаБэЪОИУзжЗћађСаЕФзжЗћДЎЁЃ |
boolean |
endsWith(String suffix)
ВтЪдДЫзжЗћДЎЪЧЗёвджИЖЈЕФКѓзКНсЪјЁЃ |
boolean |
equals(Object anObject)
БШНЯДЫзжЗћДЎгыжИЖЈЕФЖдЯѓЁЃ |
boolean |
equalsIgnoreCase(String anotherString)
НЋДЫ String гыСэвЛИі String НјааБШНЯЃЌВЛПМТЧДѓаЁаДЁЃ |
static String |
format(Locale l,
String format,
Object... args)
ЪЙгУжИЖЈЕФгябдЛЗОГЁЂИёЪНзжЗћДЎКЭВЮЪ§ЗЕЛивЛИіИёЪНЛЏзжЗћДЎЁЃ |
static String |
format(String format,
Object... args)
ЪЙгУжИЖЈЕФИёЪНзжЗћДЎКЭВЮЪ§ЗЕЛивЛИіИёЪНЛЏзжЗћДЎЁЃ |
byte[] |
getBytes()
ЪЙгУЦНЬЈФЌШЯЕФзжЗћМЏНЋДЫ String НтТыЮЊзжНкађСаЃЌВЂНЋНсЙћДцДЂЕНвЛИіаТЕФзжНкЪ§зщжаЁЃ |
void |
getBytes(int srcBegin,
int srcEnd,
byte[] dst,
int dstBegin)
вбЙ§ЪБЁЃ ИУЗНЗЈЮоЗЈНЋзжЗће§ШЗзЊЛЛЮЊзжНкЁЃДг JDK 1.1 Ц№ЃЌЭъГЩИУзЊЛЛЕФЪзбЁЗНЗЈЪЧЭЈЙ§ getBytes() ЙЙдьЗНЗЈЃЌИУЗНЗЈЪЙгУЦНЬЈЕФФЌШЯзжЗћМЏЁЃ |
byte[] |
getBytes(String charsetName)
ЪЙгУжИЖЈЕФзжЗћМЏНЋДЫ String НтТыЮЊзжНкађСаЃЌВЂНЋНсЙћДцДЂЕНвЛИіаТЕФзжНкЪ§зщжаЁЃ |
void |
getChars(int srcBegin,
int srcEnd,
char[] dst,
int dstBegin)
НЋзжЗћДгДЫзжЗћДЎИДжЦЕНФПБъзжЗћЪ§зщЁЃ |
int |
hashCode()
ЗЕЛиДЫзжЗћДЎЕФЙўЯЃТыЁЃ |
int |
indexOf(int ch)
ЗЕЛижИЖЈзжЗћдкДЫзжЗћДЎжаЕквЛДЮГіЯжДІЕФЫїв§ЁЃ |
int |
indexOf(int ch,
int fromIndex)
ДгжИЖЈЕФЫїв§ПЊЪМЫбЫїЃЌЗЕЛидкДЫзжЗћДЎжаЕквЛДЮГіЯжжИЖЈзжЗћДІЕФЫїв§ЁЃ |
int |
indexOf(String str)
ЗЕЛиЕквЛДЮГіЯжЕФжИЖЈзгзжЗћДЎдкДЫзжЗћДЎжаЕФЫїв§ЁЃ |
int |
indexOf(String str,
int fromIndex)
ДгжИЖЈЕФЫїв§ДІПЊЪМЃЌЗЕЛиЕквЛДЮГіЯжЕФжИЖЈзгзжЗћДЎдкДЫзжЗћДЎжаЕФЫїв§ЁЃ |
String |
intern()
ЗЕЛизжЗћДЎЖдЯѓЕФЙцЗЖЛЏБэЪОаЮЪНЁЃ |
int |
lastIndexOf(int ch)
ЗЕЛизюКѓвЛДЮГіЯжЕФжИЖЈзжЗћдкДЫзжЗћДЎжаЕФЫїв§ЁЃ |
int |
lastIndexOf(int ch,
int fromIndex)
ДгжИЖЈЕФЫїв§ДІПЊЪМНјааКѓЯђЫбЫїЃЌЗЕЛизюКѓвЛДЮГіЯжЕФжИЖЈзжЗћдкДЫзжЗћДЎжаЕФЫїв§ЁЃ |
int |
lastIndexOf(String str)
ЗЕЛидкДЫзжЗћДЎжазюгвБпГіЯжЕФжИЖЈзгзжЗћДЎЕФЫїв§ЁЃ |
int |
lastIndexOf(String str,
int fromIndex)
ДгжИЖЈЕФЫїв§ДІПЊЪМЯђКѓЫбЫїЃЌЗЕЛидкДЫзжЗћДЎжазюКѓвЛДЮГіЯжЕФжИЖЈзгзжЗћДЎЕФЫїв§ЁЃ |
int |
length()
ЗЕЛиДЫзжЗћДЎЕФГЄЖШЁЃ |
boolean |
matches(String regex)
ЭЈжЊДЫзжЗћДЎЪЧЗёЦЅХфИјЖЈЕФе§дђБэДяЪНЁЃ |
int |
offsetByCodePoints(int index,
int codePointOffset)
ЗЕЛиДЫ String жаДгИјЖЈЕФ index ДІЦЋвЦ codePointOffset ИіДњТыЕуЕФЫїв§ЁЃ |
boolean |
regionMatches(boolean ignoreCase,
int toffset,
String other,
int ooffset,
int len)
ВтЪдСНИізжЗћДЎЧјгђЪЧЗёЯрЕШЁЃ |
boolean |
regionMatches(int toffset,
String other,
int ooffset,
int len)
ВтЪдСНИізжЗћДЎЧјгђЪЧЗёЯрЕШЁЃ |
String |
replace(char oldChar,
char newChar)
ЗЕЛивЛИіаТЕФзжЗћДЎЃЌЫќЪЧЭЈЙ§гУ newChar ЬцЛЛДЫзжЗћДЎжаГіЯжЕФЫљга oldChar ЖјЩњГЩЕФЁЃ |
String |
replace(CharSequence target,
CharSequence replacement)
ЪЙгУжИЖЈЕФзжУцжЕЬцЛЛађСаЬцЛЛДЫзжЗћДЎЦЅХфзжУцжЕФПБъађСаЕФУПИізгзжЗћДЎЁЃ |
String |
replaceAll(String regex,
String replacement)
ЪЙгУИјЖЈЕФ replacement зжЗћДЎЬцЛЛДЫзжЗћДЎЦЅХфИјЖЈЕФе§дђБэДяЪНЕФУПИізгзжЗћДЎЁЃ |
String |
replaceFirst(String regex,
String replacement)
ЪЙгУИјЖЈЕФ replacement зжЗћДЎЬцЛЛДЫзжЗћДЎЦЅХфИјЖЈЕФе§дђБэДяЪНЕФЕквЛИізгзжЗћДЎЁЃ |
String[] |
split(String regex)
ИљОнИјЖЈЕФе§дђБэДяЪНЕФЦЅХфРДВ№ЗжДЫзжЗћДЎЁЃ |
String[] |
split(String regex,
int limit)
ИљОнЦЅХфИјЖЈЕФе§дђБэДяЪНРДВ№ЗжДЫзжЗћДЎЁЃ |
boolean |
startsWith(String prefix)
ВтЪдДЫзжЗћДЎЪЧЗёвджИЖЈЕФЧАзКПЊЪМЁЃ |
boolean |
startsWith(String prefix,
int toffset)
ВтЪдДЫзжЗћДЎЪЧЗёвджИЖЈЧАзКПЊЪМЃЌИУЧАзКвджИЖЈЫїв§ПЊЪМЁЃ |
CharSequence |
subSequence(int beginIndex,
int endIndex)
ЗЕЛивЛИіаТЕФзжЗћађСаЃЌЫќЪЧДЫађСаЕФвЛИізгађСаЁЃ |
String |
substring(int beginIndex)
ЗЕЛивЛИіаТЕФзжЗћДЎЃЌЫќЪЧДЫзжЗћДЎЕФвЛИізгзжЗћДЎЁЃ |
String |
substring(int beginIndex,
int endIndex)
ЗЕЛивЛИіаТзжЗћДЎЃЌЫќЪЧДЫзжЗћДЎЕФвЛИізгзжЗћДЎЁЃ |
char[] |
toCharArray()
НЋДЫзжЗћДЎзЊЛЛЮЊвЛИіаТЕФзжЗћЪ§зщЁЃ |
String |
toLowerCase()
ЪЙгУФЌШЯгябдЛЗОГЕФЙцдђНЋДЫ String жаЕФЫљгазжЗћЖМзЊЛЛЮЊаЁаДЁЃ |
String |
toLowerCase(Locale locale)
ЪЙгУИјЖЈ Locale ЕФЙцдђНЋДЫ String жаЕФЫљгазжЗћЖМзЊЛЛЮЊаЁаДЁЃ |
String |
toString()
ЗЕЛиДЫЖдЯѓБОЩэЃЈЫќвбОЪЧвЛИізжЗћДЎЃЁЃЉЁЃ |
String |
toUpperCase()
ЪЙгУФЌШЯгябдЛЗОГЕФЙцдђНЋДЫ String жаЕФЫљгазжЗћЖМзЊЛЛЮЊДѓаДЁЃ |
String |
toUpperCase(Locale locale)
ЪЙгУИјЖЈЕФ Locale ЙцдђНЋДЫ String жаЕФЫљгазжЗћЖМзЊЛЛЮЊДѓаДЁЃ |
String |
trim()
ЗЕЛизжЗћДЎЕФИББОЃЌКіТдЧАЕМПеАзКЭЮВВППеАзЁЃ |
static String |
valueOf(boolean b)
ЗЕЛи boolean ВЮЪ§ЕФзжЗћДЎБэЪОаЮЪНЁЃ |
static String |
valueOf(char c)
ЗЕЛи char ВЮЪ§ЕФзжЗћДЎБэЪОаЮЪНЁЃ |
static String |
valueOf(char[] data)
ЗЕЛи char Ъ§зщВЮЪ§ЕФзжЗћДЎБэЪОаЮЪНЁЃ |
static String |
valueOf(char[] data,
int offset,
int count)
ЗЕЛи char Ъ§зщВЮЪ§ЕФЬиЖЈзгЪ§зщЕФзжЗћДЎБэЪОаЮЪНЁЃ |
static String |
valueOf(double d)
ЗЕЛи double ВЮЪ§ЕФзжЗћДЎБэЪОаЮЪНЁЃ |
static String |
valueOf(float f)
ЗЕЛи float ВЮЪ§ЕФзжЗћДЎБэЪОаЮЪНЁЃ |
static String |
valueOf(int i)
ЗЕЛи int ВЮЪ§ЕФзжЗћДЎБэЪОаЮЪНЁЃ |
static String |
valueOf(long l)
ЗЕЛи long ВЮЪ§ЕФзжЗћДЎБэЪОаЮЪНЁЃ |
static String |
valueOf(Object obj)
ЗЕЛи Object ВЮЪ§ЕФзжЗћДЎБэЪОаЮЪНЁЃ |
| ДгРр java.lang.Object МЬГаЕФЗНЗЈ |
|---|
clone, finalize, getClass, notify, notifyAll, wait, wait, wait |
| зжЖЮЯъЯИаХЯЂ |
|---|
CASE_INSENSITIVE_ORDER
public static final Comparator<String> CASE_INSENSITIVE_ORDER
- вЛИіХХађ
StringЖдЯѓЕФ ComparatorЃЌЫќЕФзїгУгыcompareToIgnoreCaseЯрЭЌЁЃИУБШНЯЦїЪЧПЩађСаЛЏЕФЁЃзЂвтЃЌComparator ЮД ПМТЧЕНгябдЛЗОГЃЌвђДЫПЩФмЕМжТдкФГаЉгябдЛЗОГжаХХађаЇЙћВЛРэЯыЁЃjava.text АќЬсЙЉ Collators РДЭъГЩгябдЛЗОГУєИаЕФХХађЁЃ
- ДгвдЯТАцБОПЊЪМЃК
- 1.2
- СэЧыВЮМћЃК
Collator.compare(String, String)
| ЙЙдьЗНЗЈЯъЯИаХЯЂ |
|---|
String
public String()
- ГѕЪМЛЏвЛИіаТДДНЈЕФ
StringЖдЯѓЃЌЫќБэЪОвЛИіПезжЗћађСаЁЃзЂвтЃЌгЩгк String ЪЧВЛПЩБфЕФЃЌВЛБиЪЙгУИУЙЙдьЗНЗЈЁЃ
String
public String(String original)
- ГѕЪМЛЏвЛИіаТДДНЈЕФ
StringЖдЯѓЃЌБэЪОвЛИігыИУВЮЪ§ЯрЭЌЕФзжЗћађСаЃЛЛЛОфЛАЫЕЃЌаТДДНЈЕФзжЗћДЎЪЧИУВЮЪ§зжЗћДЎЕФвЛИіИББОЁЃгЩгк String ЪЧВЛПЩБфЕФЃЌВЛБиЪЙгУИУЙЙдьЗНЗЈЃЌГ§ЗЧашвЊoriginalЕФЯдЪНИББОЁЃ- ВЮЪ§ЃК
original- вЛИіStringЁЃ
String
public String(char[] value)
- ЗжХфвЛИіаТЕФ
StringЃЌЫќБэЪОЕБЧАзжЗћЪ§зщВЮЪ§жаАќКЌЕФзжЗћађСаЁЃИУзжЗћЪ§зщЕФФкШнвбБЛИДжЦЃЛКѓајЖдзжЗћЪ§зщЕФаоИФВЛЛсгАЯьаТДДНЈЕФзжЗћДЎЁЃ- ВЮЪ§ЃК
value- ДЫзжЗћДЎЕФГѕЪМжЕЁЃ
String
public String(char[] value,
int offset,
int count)
- ЗжХфвЛИіаТЕФ
StringЃЌЫќАќКЌРДздИУзжЗћЪ§зщВЮЪ§ЕФвЛИізгЪ§зщЕФзжЗћЁЃoffsetВЮЪ§ЪЧзгЪ§зщЕквЛИізжЗћЕФЫїв§ЃЌcountВЮЪ§жИЖЈзгЪ§зщЕФГЄЖШЁЃИУзгЪ§зщЕФФкШнвбБЛИДжЦЃЛКѓајЖдзжЗћЪ§зщЕФаоИФВЛЛсгАЯьаТДДНЈЕФзжЗћДЎЁЃ- ВЮЪ§ЃК
value- зїЮЊзжЗћдДЕФЪ§зщЁЃoffset- ГѕЪМЦЋвЦСПЁЃcount- ГЄЖШЁЃ- ХзГіЃК
IndexOutOfBoundsException- ШчЙћoffsetКЭcountВЮЪ§Ыїв§зжЗћГЌГіvalueЪ§зщЕФЗЖЮЇЁЃ
String
public String(int[] codePoints,
int offset,
int count)
- ЗжХфвЛИіаТЕФ
StringЃЌЫќАќКЌИУ Unicode ДњТыЕуЪ§зщВЮЪ§ЕФвЛИізгЪ§зщЕФзжЗћЁЃoffsetВЮЪ§ЪЧИУзгЪ§зщЕквЛИіДњТыЕуЕФЫїв§ЃЌcountВЮЪ§жИЖЈзгЪ§зщЕФГЄЖШЁЃНЋИУзгЪ§зщЕФФкШнзЊЛЛЮЊcharЃЛКѓајЖдintЪ§зщЕФаоИФВЛЛсгАЯьаТДДНЈЕФзжЗћДЎЁЃ- ВЮЪ§ЃК
codePoints- зїЮЊ Unicode ДњТыЕуЕФдДЕФЪ§зщЁЃoffset- ГѕЪМЦЋвЦСПЁЃcount- ГЄЖШЁЃ- ХзГіЃК
IllegalArgumentException- ШчЙћдкcodePointsжаЗЂЯжШЮКЮЮоаЇЕФ Unicode ДњТыЕуIndexOutOfBoundsException- ШчЙћoffsetКЭcountВЮЪ§Ыїв§зжЗћГЌГіcodePointsЪ§зщЕФЗЖЮЇЁЃ- ДгвдЯТАцБОПЊЪМЃК
- 1.5
String
@Deprecated public String(byte[] ascii, int hibyte, int offset, int count)
- вбЙ§ЪБЁЃ ИУЗНЗЈЮоЗЈНЋзжНке§ШЗзЊЛЛЮЊзжЗћЁЃДг JDK 1.1 ПЊЪМЃЌЭъГЩИУзЊЛЛЕФЪзбЁЗНЗЈЪЧЭЈЙ§
StringЙЙдьЗНЗЈЃЌЫќНгЪмвЛИізжЗћМЏУћГЦЃЌЛђепЪЙгУЦНЬЈФЌШЯЕФзжЗћМЏЁЃ- ЗжХфвЛИіаТЕФ
StringЃЌЫќИљОнвЛИі 8 ЮЛећЪ§жЕЪ§зщЕФзгЪ§зщЙЙдьЁЃoffsetВЮЪ§ЪЧИУзгЪ§зщЕФЕквЛИізжНкЕФЫїв§ЃЌcountВЮЪ§жИЖЈзгЪ§зщЕФГЄЖШЁЃзгЪ§зщжаЕФУПИі
byteЖМАДееЩЯЪіЗНЗЈзЊЛЛЮЊcharЁЃ- ВЮЪ§ЃК
ascii- вЊзЊЛЛЮЊзжЗћЕФзжНкЁЃhibyte- УПИі 16 ЮЛ Unicode зжЗћЕФЧА 8 ЮЛЁЃoffset- ГѕЪМЦЋвЦСПЁЃcount- ГЄЖШЁЃ- ХзГіЃК
IndexOutOfBoundsException- ШчЙћoffsetЛђcountВЮЪ§ЮоаЇЁЃ- СэЧыВЮМћЃК
String(byte[], int),String(byte[], int, int, java.lang.String),String(byte[], int, int),String(byte[], java.lang.String),String(byte[])
- ЗжХфвЛИіаТЕФ
String
@Deprecated public String(byte[] ascii, int hibyte)
- вбЙ§ЪБЁЃ ИУЗНЗЈЮоЗЈНЋзжНке§ШЗзЊЛЛЮЊзжЗћЁЃДг JDK 1.1 Ц№ЃЌЭъГЩИУзЊЛЛЕФЪзбЁЗНЗЈЪЧЭЈЙ§
StringЙЙдьЗНЗЈЃЌИУЗНЗЈНгЪмвЛИізжЗћМЏУћГЦЛђЪЙгУЦНЬЈЕФФЌШЯзжЗћМЏЁЃ- ЗжХфвЛИіаТЕФ
StringЃЌЫќАќКЌЕФзжЗћИљОнвЛИі 8 ЮЛећЪ§жЕЕФЪ§зщЙЙдьЁЃЕУЕНЕФзжЗћДЎжаЕФУПИізжЗћ c ЖМИљОнзжНкЪ§зщжаЕФЯргІВПЗж b ЙЙдьЃЌШчЯТЫљЪОЃКc == (char)(((hibyte & 0xff) << 8) | (b & 0xff))- ВЮЪ§ЃК
ascii- вЊзЊЛЛЮЊзжЗћЕФзжНкЁЃhibyte- УПИі 16 ЮЛ Unicode зжЗћЕФЧА 8 ЮЛЁЃ- СэЧыВЮМћЃК
String(byte[], int, int, java.lang.String),String(byte[], int, int),String(byte[], java.lang.String),String(byte[])
- ЗжХфвЛИіаТЕФ
String
public String(byte[] bytes,
int offset,
int length,
String charsetName)
throws UnsupportedEncodingException
- ЙЙдьвЛИіаТЕФ StringЃЌЗНЗЈЪЧЪЙгУжИЖЈЕФзжЗћМЏНтТызжНкЕФжИЖЈзгЪ§зщЁЃаТЕФ String ЕФГЄЖШЪЧвЛИізжЗћМЏКЏЪ§ЃЌвђДЫВЛФмЕШгкзгЪ§зщЕФГЄЖШЁЃ
ЕБИјЖЈзжНкдкИјЖЈзжЗћМЏжаЮоаЇЕФЧщПіЯТЃЌИУЙЙдьЗНЗЈЮожИЖЈЕФааЮЊЁЃЕБашвЊНјвЛВНПижЦНтТыЙ§ГЬЪБЃЌгІЪЙгУ
CharsetDecoderРрЁЃ- ВЮЪ§ЃК
bytes- вЊНтТыЮЊзжЗћЕФзжНкoffset- вЊНтТыЕФЪззжНкЕФЫїв§length- вЊНтТыЕФзжНкЪ§charsetName- ЪмжЇГжЕФcharsetЕФУћГЦ- ХзГіЃК
UnsupportedEncodingException- ШчЙћжИЖЈЕФзжЗћМЏВЛЪмжЇГжIndexOutOfBoundsException- ШчЙћ offset КЭ length ВЮЪ§Ыїв§зжЗћГЌГі bytes Ъ§зщЕФЗЖЮЇ- ДгвдЯТАцБОПЊЪМЃК
- JDK1.1
String
public String(byte[] bytes,
String charsetName)
throws UnsupportedEncodingException
- ЙЙдьвЛИіаТЕФ StringЃЌЗНЗЈЪЧЪЙгУжИЖЈЕФзжЗћМЏНтТыжИЖЈЕФзжНкЪ§зщЁЃаТЕФ String ЕФГЄЖШЪЧвЛИізжЗћМЏКЏЪ§ЃЌвђДЫВЛФмЕШгкзжНкЪ§зщЕФГЄЖШЁЃ
ЕБИјЖЈзжНкдкИјЖЈзжЗћМЏжаЮоаЇЕФЧщПіЯТЃЌИУЙЙдьЗНЗЈЮожИЖЈЕФааЮЊЁЃЕБашвЊНјвЛВНПижЦНтТыЙ§ГЬЪБЃЌгІЪЙгУ
CharsetDecoderРрЁЃ- ВЮЪ§ЃК
bytes- вЊНтТыЮЊзжЗћЕФзжНкcharsetName- ЪмжЇГжЕФcharsetЕФУћГЦ- ХзГіЃК
UnsupportedEncodingException- ШчЙћжИЖЈзжЗћМЏВЛЪмжЇГж- ДгвдЯТАцБОПЊЪМЃК
- JDK1.1
String
public String(byte[] bytes,
int offset,
int length)
- ЙЙдьвЛИіаТЕФ StringЃЌЗНЗЈЪЧЪЙгУжИЖЈЕФзжЗћМЏНтТызжНкЕФжИЖЈзгЪ§зщЁЃаТЕФ String ЕФГЄЖШЪЧвЛИізжЗћМЏКЏЪ§ЃЌвђДЫВЛФмЕШгкИУзгЪ§зщЕФГЄЖШЁЃ
ЕБИјЖЈзжНкдкИјЖЈзжЗћМЏжаЮоаЇЕФЧщПіЯТЃЌИУЙЙдьЗНЗЈЮожИЖЈЕФааЮЊЁЃЕБашвЊНјвЛВНПижЦНтТыЙ§ГЬЪБЃЌгІЪЙгУ
CharsetDecoderРрЁЃ- ВЮЪ§ЃК
bytes- вЊНтТыЮЊзжЗћЕФзжНкoffset- вЊНтТыЕФЪззжНкЕФЫїв§length- вЊНтТыЕФзжНкЪ§- ХзГіЃК
IndexOutOfBoundsException- ШчЙћoffsetКЭlengthВЮЪ§Ыїв§зжЗћГЌГіbytesЪ§зщЕФЗЖЮЇ- ДгвдЯТАцБОПЊЪМЃК
- JDK1.1
String
public String(byte[] bytes)
- ЙЙдьвЛИіаТЕФ StringЃЌЗНЗЈЪЧЪЙгУЦНЬЈЕФФЌШЯзжЗћМЏНтТызжНкЕФжИЖЈЪ§зщЁЃаТЕФ String ЕФГЄЖШЪЧвЛИізжЗћМЏКЏЪ§ЃЌвђДЫВЛФмЕШгкзжНкЪ§зщЕФГЄЖШЁЃ
ЕБИјЖЈзжНкдкИјЖЈзжЗћМЏжаЮоаЇЕФЧщПіЯТЃЌИУЙЙдьЗНЗЈЮожИЖЈЕФааЮЊЁЃЕБашвЊНјвЛВНПижЦНтТыЙ§ГЬЪБЃЌгІЪЙгУ
CharsetDecoderРрЁЃ- ВЮЪ§ЃК
bytes- вЊНтТыЮЊзжЗћЕФзжНк- ДгвдЯТАцБОПЊЪМЃК
- JDK1.1
String
public String(StringBuffer buffer)
- ЗжХфвЛИіаТЕФзжЗћДЎЃЌЫќАќКЌЕБЧААќКЌдкзжЗћДЎЛКГхЧјВЮЪ§жаЕФзжЗћађСаЁЃДЫзжЗћДЎЛКГхЧјЕФФкШнвбБЛИДжЦЃЌКѓајЖдЫќЕФаоИФВЛЛсгАЯьаТДДНЈЕФзжЗћДЎЁЃ
- ВЮЪ§ЃК
buffer- вЛИіStringBufferЁЃ
String
public String(StringBuilder builder)
- ЗжХфвЛИіаТЕФзжЗћДЎЃЌЫќАќКЌЕБЧААќКЌдкзжЗћДЎЩњГЩЦїВЮЪ§жаЕФзжЗћађСаЁЃДЫзжЗћДЎЩњГЩЦїЕФФкШнвбБЛИДжЦЃЌКѓајЖдДЫзжЗћДЎЩњГЩЦїЕФаоИФВЛЛсгАЯьаТДДНЈЕФзжЗћДЎЁЃ
ЬсЙЉИУЙЙдьЗНЗЈвдМђЛЏЕН
StringBuilderЕФЧЈвЦЁЃЭЈЙ§toStringЗНЗЈДгзжЗћДЎЩњГЩЦїжаЛёЕУзжЗћДЎПЩФмЪЧвЛжжИќПьЕФЗНЗЈЃЌвђДЫЭЈГЃзїЮЊЪзбЁЁЃ- ВЮЪ§ЃК
builder- вЛИіStringBuilder- ДгвдЯТАцБОПЊЪМЃК
- 1.5
| ЗНЗЈЯъЯИаХЯЂ |
|---|
length
public int length()
- ЗЕЛиДЫзжЗћДЎЕФГЄЖШЁЃГЄЖШЕШгкзжЗћДЎжа 16 ЮЛ Unicode зжЗћЪ§ЁЃ
- жИЖЈепЃК
- НгПк
CharSequenceжаЕФlength
- ЗЕЛиЃК
- ДЫЖдЯѓБэЪОЕФзжЗћађСаЕФГЄЖШЁЃ
charAt
public char charAt(int index)
- ЗЕЛижИЖЈЫїв§ДІЕФ
charжЕЁЃЫїв§ЗЖЮЇЮЊДг0ЕНlength() - 1ЁЃађСаЕФЕквЛИіcharжЕдкЫїв§0ДІЃЌЕкЖўИідкЫїв§1ДІЃЌвРДЫРрЭЦЃЌетРрЫЦгкЪ§зщЫїв§ЁЃШчЙћЫїв§жИЖЈЕФ
charжЕЪЧДњРэЯюЃЌдђЗЕЛиДњРэЯюжЕЁЃ- жИЖЈепЃК
- НгПк
CharSequenceжаЕФcharAt
- ВЮЪ§ЃК
index-charжЕЕФЫїв§ЁЃ- ЗЕЛиЃК
- ДЫзжЗћДЎжИЖЈЫїв§ДІЕФ
charжЕЁЃЕквЛИіcharжЕдкЫїв§0ДІЁЃ - ХзГіЃК
IndexOutOfBoundsException- ШчЙћindexВЮЪ§ЮЊИКЛђаЁгкДЫзжЗћДЎЕФГЄЖШЁЃ
codePointAt
public int codePointAt(int index)
- ЗЕЛижИЖЈЫїв§ДІЕФзжЗћЃЈUnicode ДњТыЕуЃЉЁЃИУЫїв§в§гУ
charжЕЃЈUnicode ДњТыЕЅдЊЃЉЃЌЦфЗЖЮЇДг0ЕНlength()- 1ЁЃШчЙћИјЖЈЫїв§жИЖЈЕФ
charжЕЪєгкИпДњРэЯюЗЖЮЇЃЌдђКѓајЫїв§аЁгкДЫStringЕФГЄЖШЁЃЭЌбљЃЌШчЙћКѓајЫїв§ДІЕФcharжЕЪєгкЕЭДњРэЯюЗЖЮЇЃЌдђЗЕЛиИУДњРэЯюЖдЯргІЕФдіВЙДњТыЕуЁЃЗёдђЃЌЗЕЛиИјЖЈЫїв§ДІЕФcharжЕЁЃ- ВЮЪ§ЃК
index-charжЕЕФЫїв§- ЗЕЛиЃК
- ИУ
indexДІзжЗћЕФДњТыЕужЕ - ХзГіЃК
IndexOutOfBoundsException- ШчЙћindexВЮЪ§ЮЊИКЛђаЁгкДЫзжЗћДЎЕФГЄЖШЁЃ- ДгвдЯТАцБОПЊЪМЃК
- 1.5
codePointBefore
public int codePointBefore(int index)
- ЗЕЛижИЖЈЫїв§жЎЧАЕФзжЗћЃЈUnicode ДњТыЕуЃЉЁЃИУЫїв§в§гУ
charжЕЃЈUnicode ДњТыЕЅдЊЃЉЃЌЦфЗЖЮЇДг1ЕНlengthЁЃШчЙћ
(index - 1)ДІЕФcharжЕЪєгкЕЭДњРэЯюЗЖЮЇЃЌдђ(index - 2)ЮЊЗЧИКЃЛШчЙћ(index - 2)ДІЕФcharжЕЪєгкИпЕЭРэЯюЗЖЮЇЃЌдђЗЕЛиИУДњРэЯюЖдЕФдіВЙДњТыЕужЕЁЃШчЙћindex - 1ДІЕФcharжЕЪЧЮДХфЖдЕФЕЭЃЈИпЃЉДњРэЯюЃЌдђЗЕЛиДњРэЯюжЕЁЃ- ВЮЪ§ЃК
index- гІЗЕЛиЕФДњТыЕуКѓУцЕФЫїв§- ЗЕЛиЃК
- дкИјЖЈЫїв§ЧАЕФ Unicode ДњТыЕуЁЃ
- ХзГіЃК
IndexOutOfBoundsException- ШчЙћindexВЮЪ§аЁгк 1 ЛђДѓгкДЫзжЗћДЎЕФГЄЖШЁЃ- ДгвдЯТАцБОПЊЪМЃК
- 1.5
codePointCount
public int codePointCount(int beginIndex,
int endIndex)
- ЗЕЛиДЫ
StringЕФжИЖЈЮФБОЗЖЮЇжаЕФ Unicode ДњТыЕуЪ§ЁЃЮФБОЗЖЮЇЪМгкжИЖЈЕФbeginIndexЃЌвЛжБЕНЫїв§endIndex - 1ДІЕФcharЁЃвђДЫЃЌИУЮФБОЗЖЮЇЕФГЄЖШЃЈдкcharжаЃЉЪЧendIndex-beginIndexЁЃИУЮФБОЗЖЮЇФкЮДХфЖдЕФДњРэЯюзїЮЊвЛИіДњТыЕуМЦЪ§ЁЃ- ВЮЪ§ЃК
beginIndex- ИУЮФБОЗЖЮЇЕФЕквЛИіcharЕФЫїв§ЁЃendIndex- ИУЮФБОЗЖЮЇЕФзюКѓвЛИіcharКѓУцЕФЫїв§ЁЃ- ЗЕЛиЃК
- жИЖЈЮФБОЗЖЮЇжа Unicode ДњТыЕуЕФЪ§СП
- ХзГіЃК
IndexOutOfBoundsException- ШчЙћbeginIndexЮЊИКЃЌЛђendIndexДѓгкДЫStringЕФГЄЖШЃЌЛђbeginIndexДѓгкendIndexЁЃ- ДгвдЯТАцБОПЊЪМЃК
- 1.5
offsetByCodePoints
public int offsetByCodePoints(int index,
int codePointOffset)
- ЗЕЛиДЫ
StringжаДгИјЖЈЕФindexДІЦЋвЦcodePointOffsetИіДњТыЕуЕФЫїв§ЁЃЮФБОЗЖЮЇФкгЩindexКЭcodePointOffsetИјЖЈЕФЮДХфЖдДњРэЯюИїМЦЮЊвЛИіДњТыЕуЁЃ- ВЮЪ§ЃК
index- вЊЦЋвЦЕФЫїв§codePointOffset- ДњТыЕужаЕФЦЋвЦСП- ЗЕЛиЃК
StringЕФЫїв§- ХзГіЃК
IndexOutOfBoundsException- ШчЙћindexЮЊИКЛђДѓгкДЫStringЕФГЄЖШЃЛЛђепcodePointOffsetЮЊе§ЃЌВЂЧввдindexПЊЭЗЕФзгзжЗћДЎБШcodePointOffsetОпгаИќЩйЕФДњТыЕуЃЛШчЙћcodePointOffsetЮЊИКЃЌВЂЧвindexЧАЕФзгзжЗћДЎБШcodePointOffsetЕФОјЖджЕОпгаИќЩйЕФДњТыЕуЁЃ- ДгвдЯТАцБОПЊЪМЃК
- 1.5
getChars
public void getChars(int srcBegin,
int srcEnd,
char[] dst,
int dstBegin)
- НЋзжЗћДгДЫзжЗћДЎИДжЦЕНФПБъзжЗћЪ§зщЁЃ
вЊИДжЦЕФЕквЛИізжЗћдкЫїв§
srcBeginДІЃЛвЊИДжЦЕФзюКѓвЛИізжЗћдкЫїв§srcEnd-1ДІЃЈвђДЫвЊИДжЦЕФзжЗћзмЪ§ЪЧsrcEnd-srcBeginЃЉЁЃвЊИДжЦЕНdstзгЪ§зщЕФзжЗћДгЫїв§dstBeginДІПЊЪМЃЌВЂНсЪјгкЫїв§ЃКdstbegin + (srcEnd-srcBegin) - 1- ВЮЪ§ЃК
srcBegin- зжЗћДЎжавЊИДжЦЕФЕквЛИізжЗћЕФЫїв§ЁЃsrcEnd- зжЗћДЎжавЊИДжЦЕФзюКѓвЛИізжЗћжЎКѓЕФЫїв§ЁЃdst- ФПБъЪ§зщЁЃdstBegin- ФПБъЪ§зщжаЕФЦ№ЪМЦЋвЦСПЁЃ- ХзГіЃК
IndexOutOfBoundsException- ШчЙћЯТСаШЮКЮвЛЯюЮЊ trueЃКsrcBeginЮЊИКЁЃsrcBeginДѓгкsrcEndsrcEndДѓгкДЫзжЗћДЎЕФГЄЖШdstBeginЮЊИКdstBegin+(srcEnd-srcBegin)Дѓгкdst.length
getBytes
@Deprecated public void getBytes(int srcBegin, int srcEnd, byte[] dst, int dstBegin)
- вбЙ§ЪБЁЃ ИУЗНЗЈЮоЗЈНЋзжЗће§ШЗзЊЛЛЮЊзжНкЁЃДг JDK 1.1 Ц№ЃЌЭъГЩИУзЊЛЛЕФЪзбЁЗНЗЈЪЧЭЈЙ§
getBytes()ЙЙдьЗНЗЈЃЌИУЗНЗЈЪЙгУЦНЬЈЕФФЌШЯзжЗћМЏЁЃ- НЋзжЗћДгДЫзжЗћДЎИДжЦЕНФПБъзжНкЪ§зщжаЁЃУПИізжНкНгЪеЯргІзжЗћЕФ 8 ИіЕЭЮЛЁЃВЛИДжЦУПИізжЗћЕФИпЮЛЃЌЫќУЧвВВЛВЮгыШЮКЮЗНЪНЕФзЊЛЛЁЃ
вЊИДжЦЕФЕквЛИізжЗћдкЫїв§
srcBeginДІЃЛвЊИДжЦЕФзюКѓвЛИізжЗћдкЫїв§srcEnd-1ДІЁЃвЊИДжЦЕФзжЗћзмЪ§ЮЊsrcEnd-srcBeginЁЃНЋвЊзЊЛЛЮЊзжНкЕФзжЗћИДжЦЕНdstЕФзгЪ§зщжаЃЌДгЫїв§dstBeginДІПЊЪМЃЌВЂНсЪјгкЫїв§ЃКdstbegin + (srcEnd-srcBegin) - 1- ВЮЪ§ЃК
srcBegin- зжЗћДЎжавЊИДжЦЕФЕквЛИізжЗћЕФЫїв§ЁЃsrcEnd- зжЗћДЎжавЊИДжЦЕФзюКѓвЛИізжЗћжЎКѓЕФЫїв§ЁЃdst- ФПБъЪ§зщЁЃdstBegin- ФПБъЪ§зщжаЕФЦ№ЪМЦЋвЦСПЁЃ- ХзГіЃК
IndexOutOfBoundsException- ШчЙћЯТСаШЮКЮвЛЯюЮЊ trueЃКsrcBeginЮЊИКsrcBeginДѓгкsrcEndsrcEndДѓгкДЫ String ЕФГЄЖШdstBeginЮЊИКdstBegin+(srcEnd-srcBegin)Дѓгкdst.length
- НЋзжЗћДгДЫзжЗћДЎИДжЦЕНФПБъзжНкЪ§зщжаЁЃУПИізжНкНгЪеЯргІзжЗћЕФ 8 ИіЕЭЮЛЁЃВЛИДжЦУПИізжЗћЕФИпЮЛЃЌЫќУЧвВВЛВЮгыШЮКЮЗНЪНЕФзЊЛЛЁЃ
getBytes
public byte[] getBytes(String charsetName) throws UnsupportedEncodingException
- ЪЙгУжИЖЈЕФзжЗћМЏНЋДЫ String НтТыЮЊзжНкађСаЃЌВЂНЋНсЙћДцДЂЕНвЛИіаТЕФзжНкЪ§зщжаЁЃ
ЕБДЫзжЗћДЎВЛФмдкИјЖЈЕФзжЗћМЏжаНтТыЪБЃЌИУЗНЗЈЮожИЖЈЕФааЮЊЁЃЕБашвЊНјвЛВНПижЦНтТыЙ§ГЬЪБЃЌгІЪЙгУ
CharsetEncoderРрЁЃ- ВЮЪ§ЃК
charsetName- ЪмжЇГжЕФcharsetУћГЦ- ЗЕЛиЃК
- НсЙћзжНкЪ§зщ
- ХзГіЃК
UnsupportedEncodingException- ШчЙћжИЖЈЕФзжЗћМЏВЛЪмжЇГж- ДгвдЯТАцБОПЊЪМЃК
- JDK1.1
getBytes
public byte[] getBytes()
- ЪЙгУЦНЬЈФЌШЯЕФзжЗћМЏНЋДЫ String НтТыЮЊзжНкађСаЃЌВЂНЋНсЙћДцДЂЕНвЛИіаТЕФзжНкЪ§зщжаЁЃ
ЕБДЫзжЗћДЎВЛФмдкФЌШЯЕФзжЗћМЏжаНтТыЪБЃЌИУЗНЗЈЮожИЖЈЕФааЮЊЁЃЕБашвЊНјвЛВНПижЦНтТыЙ§ГЬЪБЃЌгІЪЙгУ
CharsetEncoderРрЁЃ- ЗЕЛиЃК
- НсЙћзжНкЪ§зщ
- ДгвдЯТАцБОПЊЪМЃК
- JDK1.1
equals
public boolean equals(Object anObject)
- БШНЯДЫзжЗћДЎгыжИЖЈЕФЖдЯѓЁЃЕБЧвНіЕБИУВЮЪ§ВЛЮЊ
nullЃЌВЂЧвЪЧБэЪОгыДЫЖдЯѓЯрЭЌЕФзжЗћађСаЕФStringЖдЯѓЪБЃЌНсЙћВХЮЊtrueЁЃ- ВЮЪ§ЃК
anObject- гыДЫStringНјааБШНЯЕФЖдЯѓЁЃ- ЗЕЛиЃК
- ШчЙћ
StringЯрЕШЃЌдђЗЕЛиtrueЃЛЗёдђЗЕЛиfalseЁЃ - СэЧыВЮМћЃК
compareTo(java.lang.String),equalsIgnoreCase(java.lang.String)
contentEquals
public boolean contentEquals(StringBuffer sb)
- ЕБЧвНіЕБДЫ String БэЪОгыжИЖЈЕФ StringBuffer ЯрЭЌЕФзжЗћађСаЪБЃЌВХЗЕЛи trueЁЃ
- ВЮЪ§ЃК
sb- вЊБШНЯЕФ StringBufferЁЃ- ЗЕЛиЃК
- ЕБЧвНіЕБДЫ String БэЪОгыжИЖЈЕФ StringBuffer ЯрЭЌЕФзжЗћађСаЪБЃЌВХЗЕЛи trueЃЛЗёдђЗЕЛи falseЁЃ
- ХзГіЃК
NullPointerException- ШчЙћsbЮЊnull- ДгвдЯТАцБОПЊЪМЃК
- 1.4
contentEquals
public boolean contentEquals(CharSequence cs)
- ЕБЧвНіЕБДЫ String БэЪОгыжИЖЈађСаЯрЭЌЕФ char жЕЪБЃЌВХЗЕЛи trueЁЃ
- ВЮЪ§ЃК
cs- вЊБШНЯЕФађСаЁЃ- ЗЕЛиЃК
- ЕБЧвНіЕБДЫ String БэЪОгыжИЖЈађСаЯрЭЌЕФ char жЕЕФађСаЪБЃЛВХЗЕЛи trueЃЌЗёдђЗЕЛи falseЁЃ
- ХзГіЃК
NullPointerException- ШчЙћcsЮЊnull- ДгвдЯТАцБОПЊЪМЃК
- 1.5
equalsIgnoreCase
public boolean equalsIgnoreCase(String anotherString)
- НЋДЫ
StringгыСэвЛИіStringНјааБШНЯЃЌВЛПМТЧДѓаЁаДЁЃШчЙћСНИізжЗћДЎЕФГЄЖШЯрЕШЃЌВЂЧвСНИізжЗћДЎжаЕФЯргІзжЗћЖМЯрЕШЃЈКіТдДѓаЁаДЃЉЃЌдђШЯЮЊетСНИізжЗћДЎЪЧЯрЕШЕФЁЃдкКіТдДѓаЁаДЕФЧщПіЯТЃЌШчЙћЯТСажСЩйвЛЯюЮЊ trueЃЌдђШЯЮЊ
c1КЭc2етСНИізжЗћЯрЭЌЁЃ- етСНИізжЗћЯрЭЌЃЈЪЙгУ
==дЫЫуЗћНјааБШНЯЃЉЁЃ - ЖдУПИізжЗћгІгУЗНЗЈ
Character.toUpperCase(char)ВњЩњЯрЭЌЕФНсЙћЁЃ - ЖдУПИізжЗћгІгУЗНЗЈ
Character.toLowerCase(char)ВњЩњЯрЭЌЕФНсЙћЁЃ
- ВЮЪ§ЃК
anotherString- гыДЫStringНјааБШНЯЕФStringЁЃ- ЗЕЛиЃК
- ШчЙћВЮЪ§ВЛЮЊ
nullЃЌЧветСНИіStringдкКіТдДѓаЁаДЪБЯрЕШЃЌдђЗЕЛиtrueЃЛЗёдђЗЕЛиfalseЁЃ - СэЧыВЮМћЃК
equals(Object),Character.toLowerCase(char),Character.toUpperCase(char)
- етСНИізжЗћЯрЭЌЃЈЪЙгУ
compareTo
public int compareTo(String anotherString)
- АДзжЕфЫГађБШНЯСНИізжЗћДЎЁЃИУБШНЯЛљгкзжЗћДЎжаИїИізжЗћЕФ Unicode жЕЁЃНЋДЫ
StringЖдЯѓБэЪОЕФзжЗћађСагыВЮЪ§зжЗћДЎЫљБэЪОЕФзжЗћађСаНјааБШНЯЁЃШчЙћАДзжЕфЫГађДЫStringЖдЯѓдкВЮЪ§зжЗћДЎжЎЧАЃЌдђБШНЯНсЙћЮЊвЛИіИКећЪ§ЁЃШчЙћАДзжЕфЫГађДЫStringЖдЯѓЮЛгкВЮЪ§зжЗћДЎжЎКѓЃЌдђБШНЯНсЙћЮЊвЛИіе§ећЪ§ЁЃШчЙћетСНИізжЗћДЎЯрЕШЃЌдђНсЙћЮЊ 0ЃЛcompareToжЛгадкЗНЗЈequals(Object)ЗЕЛиtrueЪБВХЗЕЛи0ЁЃетЪЧзжЕфХХађЕФЖЈвхЁЃШчЙћетСНИізжЗћДЎВЛЭЌЃЌдђвЊУДЫќУЧдкФГИіЫїв§ДІОпгаВЛЭЌЕФзжЗћЃЌИУЫїв§ЖдЖўепОљЮЊгааЇЫїв§ЃЌвЊУДЫќУЧЕФГЄЖШВЛЭЌЃЌЛђепЭЌЪБОпБИЩЯЪіСНжжЧщПіЁЃШчЙћЫќУЧдквЛИіЛђЖрИіЫїв§ЮЛжУЩЯОпгаВЛЭЌЕФзжЗћЃЌМйЩш k ЪЧетРрЫїв§ЕФзюаЁжЕЃЛдђАДее < дЫЫуЗћШЗЖЈЕФФЧИізжЗћДЎдкЮЛжУ k ЩЯОпгаНЯаЁЕФжЕЃЌЦфзжЕфЫГађдкЦфЫћзжЗћДЎжЎЧАЁЃетжжЧщПіЯТЃЌ
compareToЗЕЛиетСНИізжЗћДЎдкЮЛжУkДІЕФСНИіВЛЭЌЕФ char жЕЃЌМДжЕЃК
ШчЙћЫќУЧУЛгаВЛЭЌЕФЫїв§ЮЛжУЃЌдђНЯЖЬзжЗћДЎдкзжЕфЫГађЩЯЮЛгкНЯГЄзжЗћДЎЕФЧАУцЁЃетжжЧщПіЯТЃЌthis.charAt(k)-anotherString.charAt(k)
compareToЗЕЛиетСНИізжЗћДЎГЄЖШЕФВЛЭЌЃЌМДжЕЃКthis.length()-anotherString.length()
- жИЖЈепЃК
- НгПк
Comparable<String>жаЕФcompareTo
- ВЮЪ§ЃК
anotherString- вЊБШНЯЕФStringЁЃ- ЗЕЛиЃК
- ШчЙћВЮЪ§зжЗћДЎЕШгкДЫзжЗћДЎЃЌдђЗЕЛи
0жЕЃЛШчЙћАДзжЕфЫГађДЫзжЗћДЎаЁгкзжЗћДЎВЮЪ§ЃЌдђЗЕЛивЛИіаЁгк0ЕФжЕЃЛШчЙћАДзжЕфЫГађДЫзжЗћДЎДѓгкзжЗћДЎВЮЪ§ЃЌдђЗЕЛивЛИіДѓгк0ЕФжЕЁЃ
compareToIgnoreCase
public int compareToIgnoreCase(String str)
- ВЛПМТЧДѓаЁаДЃЌАДзжЕфЫГађБШНЯСНИізжЗћДЎЁЃДЫЗНЗЈЗЕЛивЛИіећЪ§ЃЌЫќЕФе§ИККХЪЧЕїгУ
compareToЕФе§ИККХЃЌЕїгУЪБЪЙгУСЫзжЗћДЎЕФЙцЗЖЛЏАцБОЃЌЦфДѓаЁаДВювьвбЭЈЙ§ЖдУПИізжЗћЕїгУCharacter.toLowerCase(Character.toUpperCase(character))ЕУвдЯћГ§ЁЃзЂвтЃЌДЫЗНЗЈВЛ ПМТЧгябдЛЗОГЃЌвђДЫПЩФмдкФГаЉЬиЖЈЕФгябдЛЗОГжаВњЩњВЛРэЯыЕФХХађЁЃjava.text АќЬсЙЉ Collators РДЭъГЩгябдЛЗОГУєИаЕФХХађЁЃ
- ВЮЪ§ЃК
str- вЊБШНЯЕФStringЁЃ- ЗЕЛиЃК
- вЛИіИКећЪ§ЁЂСуЛђе§ећЪ§ЃЌЪгжИЖЈЕФ String ДѓгкЁЂЕШгкЛЙЪЧаЁгкИУ String ЖјЖЈЃЌВЛПМТЧДѓаЁаДЁЃ
- ДгвдЯТАцБОПЊЪМЃК
- 1.2
- СэЧыВЮМћЃК
Collator.compare(String, String)
regionMatches
public boolean regionMatches(int toffset,
String other,
int ooffset,
int len)
- ВтЪдСНИізжЗћДЎЧјгђЪЧЗёЯрЕШЁЃ
ИУ String ЖдЯѓЕФвЛИізгзжЗћДЎгыВЮЪ§ other ЕФвЛИізгзжЗћДЎНјааБШНЯЁЃШчЙћетСНИізгзжЗћДЎБэЪОЯрЭЌЕФзжЗћађСаЃЌдђНсЙћЮЊ trueЁЃвЊБШНЯЕФ String ЖдЯѓЕФзгзжЗћДЎДгЫїв§ toffset ДІПЊЪМЃЌГЄЖШЮЊ lenЁЃвЊБШНЯЕФ other ЕФзгзжЗћДЎДгЫїв§ ooffset ДІПЊЪМЃЌГЄЖШЮЊ lenЁЃЕБЧвНіЕБЯТСажСЩйвЛЯюЮЊ true ЪБЃЌНсЙћВХЮЊ false ЃК
- toffset ЮЊИКЁЃ
- ooffset ЮЊИКЁЃ
- toffset+len ДѓгкДЫ String ЖдЯѓЕФГЄЖШЁЃ
- ooffset+len ДѓгкСэвЛИіВЮЪ§ЕФГЄЖШЁЃ
- ДцдкФГИіаЁгк len ЕФЗЧИКећЪ§ kЃЌЫќТњзуЃКthis.charAt(toffset+k) != other.charAt(ooffset+k)
- ВЮЪ§ЃК
toffset- зжЗћДЎжазгЧјгђЕФЦ№ЪМЦЋвЦСПЁЃother- зжЗћДЎВЮЪ§ЁЃooffset- зжЗћДЎВЮЪ§жазгЧјгђЕФЦ№ЪМЦЋвЦСПЁЃlen- вЊБШНЯЕФзжЗћЪ§ЁЃ- ЗЕЛиЃК
- ШчЙћзжЗћДЎЕФжИЖЈзгЧјгђЭъШЋЦЅХфзжЗћДЎВЮЪ§ЕФжИЖЈзгЧјгђЃЌдђЗЕЛи
trueЃЛЗёдђЗЕЛиfalseЁЃ
regionMatches
public boolean regionMatches(boolean ignoreCase,
int toffset,
String other,
int ooffset,
int len)
- ВтЪдСНИізжЗћДЎЧјгђЪЧЗёЯрЕШЁЃ
НЋДЫ String ЖдЯѓЕФзгзжЗћДЎгыВЮЪ§ other ЕФзгзжЗћДЎНјааБШНЯЁЃШчЙћетСНИізгзжЗћДЎБэЪОЕФЪЧЯрЭЌЕФзжЗћађСаЃЌдђНсЙћЮЊ trueЃЌЕБЧвНіЕБ ignoreCase ЮЊ true ЪБКіТдДѓаЁаДЁЃвЊБШНЯЕФ String ЖдЯѓЕФзгзжЗћДЎДгЫїв§ toffset ДІПЊЪМЃЌГЄЖШЮЊ lenЁЃвЊБШНЯЕФ other ЕФзгзжЗћДЎДгЫїв§ ooffset ДІПЊЪМЃЌГЄЖШЮЊ lenЁЃЕБЧвНіЕБЯТСажСЩйвЛЯюЮЊ true ЪБЃЌНсЙћВХЮЊ falseЃК
- toffset ЮЊИКЁЃ
- ooffset ЮЊИКЁЃ
- toffset+len ДѓгкДЫ String ЖдЯѓЕФГЄЖШЁЃ
- ooffset+len ДѓгкСэвЛИіВЮЪ§ЕФГЄЖШЁЃ
- ignoreCase ЮЊ falseЃЌЧвДцдкФГИіаЁгк len ЕФЗЧИКећЪ§ kЃЌМДЃК
this.charAt(toffset+k) != other.charAt(ooffset+k)
- ignoreCase ЮЊ trueЃЌЧвДцдкФГИіаЁгк len ЕФЗЧИКећЪ§ kЃЌМДЃК
вдМАЃКCharacter.toLowerCase(this.charAt(toffset+k)) != Character.toLowerCase(other.charAt(ooffset+k))Character.toUpperCase(this.charAt(toffset+k)) != Character.toUpperCase(other.charAt(ooffset+k))
- ВЮЪ§ЃК
ignoreCase- ШчЙћЮЊtrueЃЌдђБШНЯзжЗћЪБКіТдДѓаЁаДЁЃtoffset- зжЗћДЎжаЕФзгЧјгђЕФЦ№ЪМЦЋвЦСПЁЃother- зжЗћДЎВЮЪ§ЁЃtoffset- зжЗћДЎВЮЪ§жаЕФзгЧјгђЕФЦ№ЪМЦЋвЦСПЁЃlen- вЊБШНЯЕФзжЗћЪ§ЁЃ- ЗЕЛиЃК
- ШчЙћДЫзжЗћДЎЕФжИЖЈзгЧјгђЦЅХфзжЗћДЎВЮЪ§ЕФжИЖЈзгЧјгђЃЌдђЗЕЛи
trueЃЛЗёдђЗЕЛиfalseЁЃЪЧЗёЭъШЋЦЅХфЛђДѓаЁаДУєИаШЁОігкignoreCaseВЮЪ§ЁЃ
startsWith
public boolean startsWith(String prefix, int toffset)
- ВтЪдДЫзжЗћДЎЪЧЗёвджИЖЈЧАзКПЊЪМЃЌИУЧАзКвджИЖЈЫїв§ПЊЪМЁЃ
- ВЮЪ§ЃК
prefix- ЧАзКЁЃtoffset- дкзжЗћДЎжаПЊЪМВщевЕФЮЛжУЁЃ- ЗЕЛиЃК
- ШчЙћИУВЮЪ§БэЪОЕФзжЗћађСаЪЧДЫЖдЯѓДгЫїв§
toffsetДІПЊЪМЕФзгзжЗћДЎЃЌдђЗЕЛиtrueЃЛЗёдђЗЕЛиfalseЁЃШчЙћtoffsetЮЊИКЛђДѓгкДЫStringЖдЯѓЕФГЄЖШЃЌдђНсЙћЮЊfalseЃЛЗёдђНсЙћгыИУБэДяЪНЕФНсЙћЯрЭЌЁЃthis.substring(toffset).startsWith(prefix)
startsWith
public boolean startsWith(String prefix)
- ВтЪдДЫзжЗћДЎЪЧЗёвджИЖЈЕФЧАзКПЊЪМЁЃ
- ВЮЪ§ЃК
prefix- ЧАзКЁЃ- ЗЕЛиЃК
- ШчЙћИУВЮЪ§БэЪОЕФзжЗћађСаЪЧДЫзжЗћДЎБэЪОЕФзжЗћађСаЕФЧАзКЃЌдђЮЊ
trueЃЛЗёдђЮЊfalseЁЃЛЙвЊзЂвтЃЌШчЙћВЮЪ§ЪЧПезжЗћДЎЃЌЛђепЕШгкгЩequals(Object)ЗНЗЈШЗЖЈЕФStringЖдЯѓЃЌдђЗЕЛиtrueЁЃ - ДгвдЯТАцБОПЊЪМЃК
- 1. 0
endsWith
public boolean endsWith(String suffix)
- ВтЪдДЫзжЗћДЎЪЧЗёвджИЖЈЕФКѓзКНсЪјЁЃ
- ВЮЪ§ЃК
suffix- КѓзКЁЃ- ЗЕЛиЃК
- ШчЙћИУВЮЪ§БэЪОЕФзжЗћађСаЪЧДЫЖдЯѓБэЪОЕФзжЗћађСаЕФКѓзКЃЌдђЗЕЛи
trueЃЛЗёдђЗЕЛиfalseЁЃзЂвтЃЌШчЙћИУВЮЪ§ЪЧПезжЗћДЎЛђЕШгкгЩequals(Object)ЗНЗЈШЗЖЈЕФStringЖдЯѓЃЌдђНсЙћЮЊtrueЁЃ
hashCode
public int hashCode()
- ЗЕЛиДЫзжЗћДЎЕФЙўЯЃТыЁЃ
StringЖдЯѓЕФЙўЯЃТыАДЯТСаЙЋЪНМЦЫуЃК
ЪЙгУs[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
intЫуЗЈЃЌетРяs[i]ЪЧзжЗћДЎЕФЕк i ИізжЗћЃЌnЪЧзжЗћДЎЕФГЄЖШЃЌ^БэЪОЧѓУнЁЃЃЈПезжЗћДЎЕФЙўЯЃТыЮЊ 0ЁЃЃЉ- ЗЕЛиЃК
- ДЫЖдЯѓЕФЙўЯЃТыжЕЁЃ
- СэЧыВЮМћЃК
Object.equals(java.lang.Object),Hashtable
indexOf
public int indexOf(int ch)
- ЗЕЛижИЖЈзжЗћдкДЫзжЗћДЎжаЕквЛДЮГіЯжДІЕФЫїв§ЁЃШчЙћдкДЫ
StringЖдЯѓБэЪОЕФзжЗћађСажаГіЯжжЕЮЊchЕФзжЗћЃЌдђЗЕЛиЕквЛДЮГіЯжИУзжЗћЕФЫїв§ЃЈвд Unicode ДњТыЕЅдЊБэЪОЃЉЁЃЖдгкЮЛгк 0 ЕН 0xFFFFЃЈАќРЈ 0 КЭ 0xFFFFЃЉЗЖЮЇФкЕФchЕФжЕЃЌЗЕЛижЕЪЧ
ЮЊ true ЕФзюаЁжЕ kЁЃЖдгкthis.charAt(k) == ch
chЕФЦфЫћжЕЃЌЗЕЛижЕЪЧ
ЮЊ true зюаЁжЕ kЁЃЮоТлФФжжЧщПіЃЌШчЙћДЫзжЗћДЎжаУЛгаетбљЕФзжЗћЃЌдђЗЕЛиthis.codePointAt(k) == ch
-1ЁЃ- ВЮЪ§ЃК
ch- вЛИізжЗћЃЈUnicode ДњТыЕуЃЉЁЃ- ЗЕЛиЃК
- дкИУЖдЯѓБэЪОЕФзжЗћађСажаЕквЛДЮГіЯжИУзжЗћЕФЫїв§ЃЌШчЙћЮДГіЯжИУзжЗћЃЌдђЗЕЛи
-1ЁЃ
indexOf
public int indexOf(int ch,
int fromIndex)
- ДгжИЖЈЕФЫїв§ПЊЪМЫбЫїЃЌЗЕЛидкДЫзжЗћДЎжаЕквЛДЮГіЯжжИЖЈзжЗћДІЕФЫїв§ЁЃ
дкДЫ
StringЖдЯѓБэЪОЕФзжЗћађСажаЃЌШчЙћДјгажЕchЕФзжЗћЕФЫїв§ВЛаЁгкfromIndexЃЌдђЗЕЛиЕквЛДЮГіЯжИУжЕЕФЫїв§ЁЃЖдгкЮЛгк 0 ЕН 0xFFFFЃЈАќРЈ 0 КЭ 0xFFFFЃЉЗЖЮЇФкЕФchжЕЃЌЗЕЛижЕЪЧ
ЮЊ true ЕФзюаЁжЕ kЁЃЖдгк(this.charAt(k) == ch) && (k >= fromIndex)
chЕФЦфЫћжЕЃЌЗЕЛижЕЪЧ
ЮЊ true ЕФзюаЁжЕ kЁЃдкШЮКЮЧщПіЯТЃЌШчЙћДЫзжЗћДЎжаУЛгаетбљЕФзжЗћдкЮЛжУ(this.codePointAt(k) == ch) && (k >= fromIndex)
fromIndexДІЛђЦфКѓГіЯжЃЌдђЗЕЛи-1ЁЃfromIndexЕФжЕУЛгаЯожЦЁЃШчЙћЫќЮЊИКЃЌЫќКЭ 0 ОпгаЭЌбљЕФаЇЙћЃКНЋЫбЫїећИізжЗћДЎЁЃШчЙћЫќДѓгкДЫзжЗћДЎЕФГЄЖШЃЌдђЫќОпгаЕШгкДЫзжЗћДЎГЄЖШЕФЯрЭЌаЇЙћЃКЗЕЛи-1ЁЃЫљгаЫїв§ЖМдк
charжЕжажИЖЈЃЈUnicode ДњТыЕЅдЊЃЉЁЃ- ВЮЪ§ЃК
ch- вЛИізжЗћЃЈUnicode ДњТыЕуЃЉЁЃfromIndex- ПЊЪМЫбЫїЕФЫїв§ЁЃ- ЗЕЛиЃК
- дкДЫЖдЯѓБэЪОЕФзжЗћађСажаЕквЛДЮГіЯжЕФДѓгкЛђЕШгк
fromIndexЕФзжЗћЕФЫїв§ЃЌШчЙћЮДГіЯжИУзжЗћЃЌдђЗЕЛи-1ЁЃ
lastIndexOf
public int lastIndexOf(int ch)
- ЗЕЛизюКѓвЛДЮГіЯжЕФжИЖЈзжЗћдкДЫзжЗћДЎжаЕФЫїв§ЁЃЖдгкЮЛгк 0 ЕН 0xFFFFЃЈАќРЈ 0 КЭ 0xFFFFЃЉЗЖЮЇФкЕФ
chЕФжЕЃЌЗЕЛиЕФЫїв§ЃЈUnicode ДњТыЕЅдЊЃЉЪЧ
ЮЊ true зюДѓжЕ kЁЃЖдгкthis.charAt(k) == ch
chЕФЦфЫћжЕЃЌМДЮЊ
ЮЊ true ЕФзюДѓжЕ kЁЃдкШЮвЛжжЧщПіЯТЃЌШчЙћДЫзжЗћДЎжаУЛгаетбљЕФзжЗћГіЯжЃЌдђЗЕЛиthis.codePointAt(k) == ch
-1ЁЃДгзюКѓвЛИізжЗћПЊЪМКѓЯђЫбЫїДЫStringЁЃ- ВЮЪ§ЃК
ch- вЛИізжЗћЃЈUnicode ДњТыЕуЃЉЁЃ- ЗЕЛиЃК
- дкДЫЖдЯѓБэЪОЕФзжЗћађСажазюКѓвЛДЮГіЯжИУзжЗћЕФЫїв§ЃЌШчЙћЮДГіЯжИУзжЗћЃЌдђЗЕЛи
-1ЁЃ
lastIndexOf
public int lastIndexOf(int ch,
int fromIndex)
- ДгжИЖЈЕФЫїв§ДІПЊЪМНјааКѓЯђЫбЫїЃЌЗЕЛизюКѓвЛДЮГіЯжЕФжИЖЈзжЗћдкДЫзжЗћДЎжаЕФЫїв§ЁЃЖдгкЮЛгк 0 ЕН 0xFFFFЃЈАќРЈ 0 КЭ 0xFFFFЃЉЗЖЮЇФкЕФ
chжЕЃЌЗЕЛиЕФЫїв§ЪЧ
ЮЊ true ЕФзюДѓжЕ kЁЃЖдгк(this.charAt(k) == ch) && (k <= fromIndex)
chЕФЦфЫћжЕЃЌМДЮЊ
ЮЊ true ЕФзюДѓжЕ kЁЃдкШЮвЛжжЧщПіЯТЃЌШчЙћДЫзжЗћДЎжаУЛгаетбљЕФзжЗћдкЮЛжУ(this.codePointAt(k) == ch) && (k <= fromIndex)
fromIndexДІЛђЦфЧАГіЯжЃЌдђЗЕЛи-1ЁЃЫљгаЕФЫїв§ЖМвд
charжЕжИЖЈЃЈUnicode ДњТыЕЅдЊЃЉЁЃ- ВЮЪ§ЃК
ch- вЛИізжЗћЃЈUnicode ДњТыЕуЃЉЁЃfromIndex- ПЊЪМЫбЫїЕФЫїв§ЁЃfromIndexЕФжЕУЛгаЯожЦЁЃШчЙћЫќДѓгкЛђЕШгкДЫзжЗћДЎЕФГЄЖШЃЌдђЫќОпгагыаЁгкДЫзжЗћДЎГЄЖШЕФЯрЭЌаЇЙћЃКНЋЫбЫїећИізжЗћДЎЁЃШчЙћЫќЮЊИКЃЌдђЫќЕФаЇЙћгыЫќЮЊ -1 ЪЧЯрЭЌЕФЃКЗЕЛи -1ЁЃ- ЗЕЛиЃК
- дкДЫЖдЯѓБэЪОЕФзжЗћађСажазюКѓвЛДЮГіЯжЕФДѓгкЛђЕШгк
fromIndexЕФзжЗћЕФЫїв§ЃЌШчЙћдкИУЕужЎЧАЮДГіЯжИУзжЗћЃЌдђЗЕЛи-1ЁЃ
indexOf
public int indexOf(String str)
- ЗЕЛиЕквЛДЮГіЯжЕФжИЖЈзгзжЗћДЎдкДЫзжЗћДЎжаЕФЫїв§ЁЃЗЕЛиЕФећЪ§ЪЧ
ЮЊthis.startsWith(str, k)
trueЕФзюаЁжЕ kЁЃ- ВЮЪ§ЃК
str- ШЮвтзжЗћДЎЁЃ- ЗЕЛиЃК
- ШчЙћзжЗћДЎВЮЪ§зїЮЊвЛИізгзжЗћДЎдкДЫЖдЯѓжаГіЯжЃЌдђЗЕЛиЕквЛИіетбљЕФзгзжЗћДЎЕФЕквЛИізжЗћЕФЫїв§ЃЛШчЙћЫќВЛзїЮЊвЛИізгзжЗћДЎГіЯжЃЌдђЗЕЛи
-1ЁЃ
indexOf
public int indexOf(String str, int fromIndex)
- ДгжИЖЈЕФЫїв§ДІПЊЪМЃЌЗЕЛиЕквЛДЮГіЯжЕФжИЖЈзгзжЗћДЎдкДЫзжЗћДЎжаЕФЫїв§ЁЃЗЕЛиЕФећЪ§ЪЧзюаЁжЕ kЃЌЫќТњзуЃК
ШчЙћВЛДцдкетбљЕФ k жЕЃЌдђЗЕЛи -1ЁЃk >= Math.min(fromIndex, str.length()) && this.startsWith(str, k)- ВЮЪ§ЃК
str- вЊЫбЫїЕФзгзжЗћДЎЁЃfromIndex- ПЊЪМЫбЫїЕФЫїв§ЮЛжУЁЃ- ЗЕЛиЃК
- ДгжИЖЈЕФЫїв§ДІПЊЪМЃЌЗЕЛиЕквЛДЮГіЯжЕФжИЖЈзгзжЗћДЎдкДЫзжЗћДЎжаЕФЫїв§ЁЃ
lastIndexOf
public int lastIndexOf(String str)
- ЗЕЛидкДЫзжЗћДЎжазюгвБпГіЯжЕФжИЖЈзгзжЗћДЎЕФЫїв§ЁЃНЋзюгвБпЕФПезжЗћДЎ "" ЪгзїЗЂЩњдкЫїв§жЕ
this.length()ДІЁЃЗЕЛиЕФЫїв§ЪЧ
ЮЊ true ЕФзюДѓжЕ kЁЃthis.startsWith(str, k)
- ВЮЪ§ЃК
str- вЊЫбЫїЕФзгзжЗћДЎЁЃ- ЗЕЛиЃК
- ШчЙћдкДЫЖдЯѓжазжЗћДЎВЮЪ§зїЮЊвЛИізгзжЗћДЎГіЯжвЛДЮЛђЖрДЮЃЌдђЗЕЛизюКѓвЛИіетбљЕФзгзжЗћДЎЕФЕквЛИізжЗћЁЃШчЙћЫќВЛзїЮЊвЛИізгзжЗћДЎГіЯжЃЌдђЗЕЛи
-1ЁЃ
lastIndexOf
public int lastIndexOf(String str, int fromIndex)
- ДгжИЖЈЕФЫїв§ДІПЊЪМЯђКѓЫбЫїЃЌЗЕЛидкДЫзжЗћДЎжазюКѓвЛДЮГіЯжЕФжИЖЈзгзжЗћДЎЕФЫїв§ЁЃЗЕЛиЕФећЪ§ЪЧзюДѓжЕ kЃЌЫќТњзуЃК
ШчЙћВЛДцдкетбљЕФ k жЕЃЌдђЗЕЛи -1ЁЃk <= Math.min(fromIndex, str.length()) && this.startsWith(str, k)- ВЮЪ§ЃК
str- вЊЫбЫїЕФзгзжЗћДЎЁЃfromIndex- ПЊЪМЫбЫїЕФЫїв§ЮЛжУЁЃ- ЗЕЛиЃК
- зюКѓвЛДЮГіЯжЕФжИЖЈзгзжЗћДЎдкДЫзжЗћДЎжаЕФЫїв§ЁЃ
substring
public String substring(int beginIndex)
- ЗЕЛивЛИіаТЕФзжЗћДЎЃЌЫќЪЧДЫзжЗћДЎЕФвЛИізгзжЗћДЎЁЃИУзгзжЗћДЎЪМгкжИЖЈЫїв§ДІЕФзжЗћЃЌвЛжБЕНДЫзжЗћДЎФЉЮВЁЃ
Р§ШчЃК
"unhappy".substring(2) returns "happy" "Harbison".substring(3) returns "bison" "emptiness".substring(9) returns "" (an empty string)
- ВЮЪ§ЃК
beginIndex- ПЊЪМДІЕФЫїв§ЃЈАќРЈЃЉЁЃ- ЗЕЛиЃК
- жИЖЈЕФзгзжЗћДЎЁЃ
- ХзГіЃК
IndexOutOfBoundsException- ШчЙћbeginIndexЮЊИКЛђДѓгкДЫStringЖдЯѓЕФГЄЖШЁЃ
substring
public String substring(int beginIndex, int endIndex)
- ЗЕЛивЛИіаТзжЗћДЎЃЌЫќЪЧДЫзжЗћДЎЕФвЛИізгзжЗћДЎЁЃИУзгзжЗћДЎДгжИЖЈЕФ
beginIndexДІПЊЪМЃЌвЛжБЕНЫїв§endIndex - 1ДІЕФзжЗћЁЃвђДЫЃЌИУзгзжЗћДЎЕФГЄЖШЮЊendIndex-beginIndexЁЃЪОР§ЃК
"hamburger".substring(4, 8) returns "urge" "smiles".substring(1, 5) returns "mile"
- ВЮЪ§ЃК
beginIndex- ПЊЪМДІЕФЫїв§ЃЈАќРЈЃЉЁЃendIndex- НсЪјДІЕФЫїв§ЃЈВЛАќРЈЃЉЁЃ- ЗЕЛиЃК
- жИЖЈЕФзгзжЗћДЎЁЃ
- ХзГіЃК
IndexOutOfBoundsException- ШчЙћbeginIndexЮЊИКЃЌЛђendIndexДѓгкДЫStringЖдЯѓЕФГЄЖШЃЌЛђbeginIndexДѓгкendIndexЁЃ
subSequence
public CharSequence subSequence(int beginIndex, int endIndex)
- ЗЕЛивЛИіаТЕФзжЗћађСаЃЌЫќЪЧДЫађСаЕФвЛИізгађСаЁЃ
етжжаЮЪНЕФЗНЗЈЕїгУЃК
гыЯТСаЗНЗЈЕїгУЭъШЋЯрЭЌЃКstr.subSequence(begin, end)
ЖЈвхДЫЗНЗЈвдЪЙ String РрФмЙЛЪЕЯжstr.substring(begin, end)
CharSequenceНгПкЁЃ- жИЖЈепЃК
- НгПк
CharSequenceжаЕФsubSequence
- ВЮЪ§ЃК
beginIndex- ПЊЪМДІЕФЫїв§ЃЈАќРЈЃЉЁЃendIndex- НсЪјДІЕФЫїв§ЃЈВЛАќРЈЃЉЁЃ- ЗЕЛиЃК
- жИЖЈзгађСаЁЃ
- ХзГіЃК
IndexOutOfBoundsException- ШчЙћ beginIndex Лђ endIndex ЮЊИКЃЌШчЙћ endIndex Дѓгк length() Лђ beginIndex Дѓгк startIndex- ДгвдЯТАцБОПЊЪМЃК
- 1.4
concat
public String concat(String str)
- НЋжИЖЈзжЗћДЎСЊЕНДЫзжЗћДЎЕФНсЮВЁЃ
ШчЙћВЮЪ§зжЗћДЎЕФГЄЖШЮЊ
0ЃЌдђЗЕЛиДЫStringЖдЯѓЁЃЗёдђЃЌДДНЈвЛИіаТЕФStringЖдЯѓЃЌгУРДБэЪОгЩДЫStringЖдЯѓБэЪОЕФзжЗћађСаКЭгЩВЮЪ§зжЗћДЎБэЪОЕФзжЗћађСаДЎСЊЖјГЩЕФзжЗћађСаЁЃЪОР§ЃК
"cares".concat("s") returns "caress" "to".concat("get").concat("her") returns "together"- ВЮЪ§ЃК
str- ДЎСЊЕНДЫStringНсЮВЕФStringЁЃ- ЗЕЛиЃК
- вЛИізжЗћДЎЃЌЫќБэЪОДЫЖдЯѓЕФзжЗћКѓУцДЎСЊзжЗћДЎВЮЪ§ЕФзжЗћЁЃ
replace
public String replace(char oldChar, char newChar)
- ЗЕЛивЛИіаТЕФзжЗћДЎЃЌЫќЪЧЭЈЙ§гУ
newCharЬцЛЛДЫзжЗћДЎжаГіЯжЕФЫљгаoldCharЖјЩњГЩЕФЁЃШчЙћ
oldCharдкДЫStringЖдЯѓБэЪОЕФзжЗћађСажаУЛгаГіЯжЃЌдђЗЕЛиЖдДЫStringЖдЯѓЕФв§гУЁЃЗёдђЃЌДДНЈвЛИіаТЕФStringЖдЯѓЃЌгУРДБэЪОгыДЫStringЖдЯѓБэЪОЕФзжЗћађСаЯрЕШЕФзжЗћађСаЃЌГ§СЫУПИіГіЯжЕФoldCharЖМБЛвЛИіnewCharЬцЛЛжЎЭтЁЃЪОР§ЃК
"mesquite in your cellar".replace('e', 'o') returns "mosquito in your collar" "the war of baronets".replace('r', 'y') returns "the way of bayonets" "sparring with a purple porpoise".replace('p', 't') returns "starring with a turtle tortoise" "JonL".replace('q', 'x') returns "JonL" (no change)- ВЮЪ§ЃК
oldChar- дРДЕФзжЗћЁЃnewChar- аТзжЗћЁЃ- ЗЕЛиЃК
- вЛИіДгДЫзжЗћДЎХЩЩњЕФзжЗћДЎЃЌЗНЗЈЪЧдкУПИіГіЯж
oldCharЕФЕиЗНгУnewCharЬцЛЛЁЃ
matches
public boolean matches(String regex)
- ЭЈжЊДЫзжЗћДЎЪЧЗёЦЅХфИјЖЈЕФе§дђБэДяЪНЁЃ
ДЫЗНЗЈЕїгУЕФ str.matches(regex) аЮЪНгывдЯТБэДяЪНВњЩњЭъШЋЯрЭЌЕФНсЙћЃК
Pattern.matches(regex, str)- ВЮЪ§ЃК
regex- гУРДЦЅХфДЫзжЗћДЎЕФе§дђБэДяЪН- ЗЕЛиЃК
- ЕБЧвНіЕБДЫзжЗћДЎЦЅХфИјЖЈЕФе§дђБэДяЪНЪБЃЌВХЗЕЛи true
- ХзГіЃК
PatternSyntaxException- ШчЙће§дђБэДяЪНЕФгяЗЈЮоаЇ- ДгвдЯТАцБОПЊЪМЃК
- 1.4
- СэЧыВЮМћЃК
Pattern
contains
public boolean contains(CharSequence s)
- ЕБЧвНіЕБДЫзжЗћДЎАќКЌ char жЕЕФжИЖЈађСаЪБЃЌВХЗЕЛи trueЁЃ
- ВЮЪ§ЃК
s- вЊЫбЫїЕФађСа- ЗЕЛиЃК
- ШчЙћДЫзжЗћДЎАќКЌ
sЃЌдђЗЕЛи trueЃЌЗёдђЗЕЛи false - ХзГіЃК
NullPointerException- ШчЙћsЮЊnull- ДгвдЯТАцБОПЊЪМЃК
- 1.5
replaceFirst
public String replaceFirst(String regex, String replacement)
- ЪЙгУИјЖЈЕФ replacement зжЗћДЎЬцЛЛДЫзжЗћДЎЦЅХфИјЖЈЕФе§дђБэДяЪНЕФЕквЛИізгзжЗћДЎЁЃ
ДЫЗНЗЈЕїгУЕФ str.replaceFirst(regex, repl) аЮЪНВњЩњгывдЯТБэДяЪНЭъШЋЯрЭЌЕФНсЙћЃК
Pattern.compile(regex).matcher(str).replaceFirst(repl)- ВЮЪ§ЃК
regex- гУРДЦЅХфДЫзжЗћДЎЕФе§дђБэДяЪН- ЗЕЛиЃК
- ЕУЕНЕФ String
- ХзГіЃК
PatternSyntaxException- ШчЙће§дђБэДяЪНЕФгяЗЈЮоаЇ- ДгвдЯТАцБОПЊЪМЃК
- 1.4
- СэЧыВЮМћЃК
Pattern
replaceAll
public String replaceAll(String regex, String replacement)
- ЪЙгУИјЖЈЕФ replacement зжЗћДЎЬцЛЛДЫзжЗћДЎЦЅХфИјЖЈЕФе§дђБэДяЪНЕФУПИізгзжЗћДЎЁЃ
ДЫЗНЗЈЕїгУЕФ str.replaceAll(regex, repl) аЮЪНВњЩњгывдЯТБэДяЪНЭъШЋЯрЭЌЕФНсЙћЃК
Pattern.compile(regex).matcher(str).replaceAll(repl)- ВЮЪ§ЃК
regex- гУРДЦЅХфДЫзжЗћДЎЕФе§дђБэДяЪН- ЗЕЛиЃК
- ЕУЕНЕФ String
- ХзГіЃК
PatternSyntaxException- ШчЙће§дђБэДяЪНЕФгяЗЈЮоаЇ- ДгвдЯТАцБОПЊЪМЃК
- 1.4
- СэЧыВЮМћЃК
Pattern
replace
public String replace(CharSequence target, CharSequence replacement)
- ЪЙгУжИЖЈЕФзжУцжЕЬцЛЛађСаЬцЛЛДЫзжЗћДЎЦЅХфзжУцжЕФПБъађСаЕФУПИізгзжЗћДЎЁЃИУЬцЛЛДгДЫзжЗћДЎЕФПЊЪМвЛжБЕННсЪјЃЌР§ШчЃЌгУ "b" ЬцЛЛзжЗћДЎ "aaa" жаЕФ "aa" НЋЩњГЩ "ba" ЖјВЛЪЧ "ab"ЁЃ
- ВЮЪ§ЃК
target- вЊБЛЬцЛЛЕФ char жЕађСаreplacement- char жЕЕФЬцЛЛађСа- ЗЕЛиЃК
- ЕУЕНЕФзжЗћДЎ
- ХзГіЃК
NullPointerException- ШчЙћtargetЛђreplacementЮЊnullЁЃ- ДгвдЯТАцБОПЊЪМЃК
- 1.5
split
public String[] split(String regex, int limit)
- ИљОнЦЅХфИјЖЈЕФе§дђБэДяЪНРДВ№ЗжДЫзжЗћДЎЁЃ
ДЫЗНЗЈЗЕЛиЕФЪ§зщАќКЌДЫзжЗћДЎЕФУПИізгзжЗћДЎЃЌетаЉзгзжЗћДЎгЩСэвЛИіЦЅХфИјЖЈЕФБэДяЪНЕФзгзжЗћДЎжежЙЛђгЩзжЗћДЎНсЪјРДжежЙЁЃЪ§зщжаЕФзгзжЗћДЎАДЫќУЧдкДЫзжЗћДЎжаЕФЫГађХХСаЁЃШчЙћБэДяЪНВЛЦЅХфЪфШыЕФШЮКЮВПЗжЃЌдђНсЙћЪ§зщжЛОпгавЛИідЊЫиЃЌМДДЫзжЗћДЎЁЃ
limit ВЮЪ§ПижЦФЃЪНгІгУЕФДЮЪ§ЃЌвђДЫгАЯьНсЙћЪ§зщЕФГЄЖШЁЃШчЙћИУЯожЦ n Дѓгк 0ЃЌдђФЃЪННЋБЛзюЖргІгУ n - 1 ДЮЃЌЪ§зщЕФГЄЖШНЋВЛЛсДѓгк nЃЌЖјЧвЪ§зщЕФзюКѓЯюНЋАќКЌГЌГізюКѓЦЅХфЕФЖЈНчЗћЕФЫљгаЪфШыЁЃШчЙћ n ЮЊЗЧе§ЃЌдђФЃЪННЋБЛгІгУОЁПЩФмЖрЕФДЮЪ§ЃЌЖјЧвЪ§зщПЩвдЪЧШЮвтГЄЖШЁЃШчЙћ n ЮЊСуЃЌдђФЃЪННЋБЛгІгУОЁПЩФмЖрЕФДЮЪ§ЃЌЪ§зщПЩгаШЮКЮГЄЖШЃЌВЂЧвНсЮВПезжЗћДЎНЋБЛЖЊЦњЁЃ
Р§ШчЃЌзжЗћДЎ "boo:and:foo" ЪЙгУетаЉВЮЪ§ПЩЩњГЩЯТСаНсЙћЃК
Regex Limit НсЙћ : 2 { "boo", "and:foo" } : 5 { "boo", "and", "foo" } : -2 { "boo", "and", "foo" } o 5 { "b", "", ":and:f", "", "" } o -2 { "b", "", ":and:f", "", "" } o 0 { "b", "", ":and:f" } етжжаЮЪНЕФЗНЗЈЕїгУ str.split(regex, n) ВњЩњгывдЯТБэДяЪНЭъШЋЯрЭЌЕФНсЙћЃК
Pattern.compile(regex).split(str, n)- ВЮЪ§ЃК
regex- ЖЈНче§дђБэДяЪНlimit- НсЙћуажЕЃЌШчЩЯЫљЪі- ЗЕЛиЃК
- зжЗћДЎЪ§зщЃЌИљОнИјЖЈе§дђБэДяЪНЕФЦЅХфРДВ№ЗжДЫзжЗћДЎЃЌДгЖјЩњГЩДЫЪ§зщ
- ХзГіЃК
PatternSyntaxException- ШчЙће§дђБэДяЪНЕФгяЗЈЮоаЇ- ДгвдЯТАцБОПЊЪМЃК
- 1.4
- СэЧыВЮМћЃК
Pattern
split
public String[] split(String regex)
- ИљОнИјЖЈЕФе§дђБэДяЪНЕФЦЅХфРДВ№ЗжДЫзжЗћДЎЁЃ
ИУЗНЗЈЕФзїгУОЭЯёЪЧЪЙгУИјЖЈЕФБэДяЪНКЭЯожЦВЮЪ§ 0 РДЕїгУСНВЮЪ§
splitЗНЗЈЁЃвђДЫЃЌНсЙћЪ§зщжаВЛАќРЈНсЮВПезжЗћДЎЁЃР§ШчЃЌзжЗћДЎ "boo:and:foo" ВњЩњДјгаЯТУцетаЉБэДяЪНЕФНсЙћЃК
Regex НсЙћ : { "boo", "and", "foo" } o { "b", "", ":and:f" } - ВЮЪ§ЃК
regex- ЖЈНче§дђБэДяЪН- ЗЕЛиЃК
- зжЗћДЎЪ§зщЃЌИљОнИјЖЈе§дђБэДяЪНЕФЦЅХфРДВ№ЗжДЫзжЗћДЎЃЌДгЖјЩњГЩДЫЪ§зщЁЃ
- ХзГіЃК
PatternSyntaxException- ШчЙће§дђБэДяЪНЕФгяЗЈЮоаЇ- ДгвдЯТАцБОПЊЪМЃК
- 1.4
- СэЧыВЮМћЃК
Pattern
toLowerCase
public String toLowerCase(Locale locale)
- ЪЙгУИјЖЈ
LocaleЕФЙцдђНЋДЫStringжаЕФЫљгазжЗћЖМзЊЛЛЮЊаЁаДЁЃДѓаЁаДгГЩфЙиЯЕЛљгкгЩCharacterРржИЖЈЕФ Unicode Standard АцБОЁЃгЩгкДѓаЁаДгГЩфЙиЯЕВЂВЛзмЪЧ 1:1 ЕФзжЗћгГЩфЙиЯЕЃЌЕУЕНЕФStringПЩФмОпгаВЛЭЌгкдЪМStringЕФГЄЖШЁЃЯТБэжаИјГіСЫМИИіаЁаДгГЩфЙиЯЕЕФР§згЃК
гябдЛЗОГЕФДњТы ДѓаДзжФИ аЁаДзжФИ УшЪі tr (Turkish) \u0130 \u0069 ДѓаДзжФИ IЃЌЩЯУцгаЕу -> аЁаДзжФИ i tr (Turkish) \u0049 \u0131 ДѓаДзжФИ I -> аЁаДзжФИ iЃЌЮоЕу (all) French Fries french fries НЋзжЗћДЎжаЕФЫљгазжЗћЖМаЁаД (all) 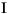
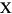
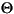
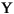
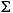
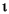
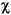
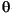
НЋзжЗћДЎжаЕФЫљгазжЗћЖМаЁаД - ВЮЪ§ЃК
locale- ЪЙгУДЫгябдЛЗОГЕФДѓаЁаДзЊЛЛЙцдђ- ЗЕЛиЃК
- вЊзЊЛЛЮЊаЁаДЕФ
StringЁЃ - ДгвдЯТАцБОПЊЪМЃК
- 1.1
- СэЧыВЮМћЃК
toLowerCase(),toUpperCase(),toUpperCase(Locale)
toLowerCase
public String toLowerCase()
- ЪЙгУФЌШЯгябдЛЗОГЕФЙцдђНЋДЫ
StringжаЕФЫљгазжЗћЖМзЊЛЛЮЊаЁаДЁЃетЕШаЇгкЕїгУtoLowerCase(Locale.getDefault())ЁЃ- ЗЕЛиЃК
- вЊзЊЛЛЮЊаЁаДЕФ
StringЁЃ - СэЧыВЮМћЃК
toLowerCase(Locale)
toUpperCase
public String toUpperCase(Locale locale)
- ЪЙгУИјЖЈЕФ
LocaleЙцдђНЋДЫStringжаЕФЫљгазжЗћЖМзЊЛЛЮЊДѓаДЁЃДѓаЁаДгГЩфЙиЯЕЛљгкгЩCharacterРржИЖЈЕФ Unicode Standard АцБОЁЃгЩгкДѓаЁаДгГЩфЙиЯЕВЂВЛзмЪЧ 1:1 ЕФзжЗћгГЩфЙиЯЕЃЌЕУЕНЕФStringПЩФмОпгаВЛЭЌгкдЪМStringЕФГЄЖШЁЃЯТБэжаЪЧгябдЛЗОГУєИаКЭ 1:M ДѓаЁаДгГЩфЙиЯЕЕФвЛаЉР§згЁЃ
гябдЛЗОГЕФДњТы аЁаД ДѓаД УшЪі tr (Turkish) \u0069 \u0130 аЁаДзжФИ i -> ДѓаДзжФИ IЃЌЩЯУцгаЕу tr (Turkish) \u0131 \u0049 ЮоЕуЕФаЁаДзжФИ -> ДѓаДзжФИ I (all) \u00df \u0053 \u0053 аЁаДзжФИ sharp s -> СНИізжФИЃКSS (all) Fahrvergnügen FAHRVERGNÜN - ВЮЪ§ЃК
locale- гУгкДЫгябдЛЗОГЕФДѓаЁаДзЊЛЛЙцдђ- ЗЕЛиЃК
- вЊзЊЛЛЮЊДѓаДЕФ
StringЁЃ - ДгвдЯТАцБОПЊЪМЃК
- 1.1
- СэЧыВЮМћЃК
toUpperCase(),toLowerCase(),toLowerCase(Locale)
toUpperCase
public String toUpperCase()
- ЪЙгУФЌШЯгябдЛЗОГЕФЙцдђНЋДЫ
StringжаЕФЫљгазжЗћЖМзЊЛЛЮЊДѓаДЁЃДЫЗНЗЈЕШаЇгкtoUpperCase(Locale.getDefault())ЁЃ- ЗЕЛиЃК
- вЊзЊЛЛЮЊДѓаДЕФ
StringЁЃ - СэЧыВЮМћЃК
toUpperCase(Locale)
trim
public String trim()
- ЗЕЛизжЗћДЎЕФИББОЃЌКіТдЧАЕМПеАзКЭЮВВППеАзЁЃ
ШчЙћДЫ
StringЖдЯѓБэЪОвЛИіПезжЗћађСаЃЌЛђепДЫStringЖдЯѓБэЪОЕФзжЗћађСаЕФЕквЛИіКЭзюКѓвЛИізжЗћЕФДњТыЖМДѓгк'\u0020'ЃЈПеИёзжЗћЃЉЃЌдђЗЕЛиЖдДЫStringЖдЯѓЕФв§гУЁЃЗёдђЃЌШєзжЗћДЎжаУЛгаДњТыДѓгк
'\u0020'ЕФзжЗћЃЌдђДДНЈВЂЗЕЛивЛИіБэЪОПезжЗћДЎЕФаТЕФStringЖдЯѓЁЃЗёдђЃЌМйЖЈ k ЮЊДњТыДѓгк
'\u0020'ЕФЕквЛИізжЗћЕФЫїв§ЃЌm ЮЊДњТыДѓгк'\u0020'ЕФзюКѓвЛИізжЗћЕФЫїв§ЁЃДДНЈвЛИіаТЕФStringЖдЯѓЃЌЫќБэЪОДЫзжЗћДЎжаДгЫїв§ k ДІЕФзжЗћПЊЪМЃЌЕНЫїв§ m ДІЕФзжЗћНсЪјЕФзгзжЗћДЎЃЌвВОЭЪЧthis.substring(k, m+1)ЕФНсЙћЁЃДЫЗНЗЈгУгкНиШЅзжЗћДЎДгЭЗЕНЮВЕФПеАзЃЈШчЩЯУцЫљЖЈвхЃЉЁЃ
- ЗЕЛиЃК
- ДЫзжЗћДЎвЦГ§СЫЧАЕМКЭЮВВППеАзЕФИББОЃЌШчЙћУЛгаЧАЕМКЭЮВВППеАзЃЌдђЗЕЛиДЫзжЗћДЎЁЃ
toString
public String toString()
- ЗЕЛиДЫЖдЯѓБОЩэЃЈЫќвбОЪЧвЛИізжЗћДЎЃЁЃЉЁЃ
- жИЖЈепЃК
- НгПк
CharSequenceжаЕФtoString - ИВИЧЃК
- Рр
ObjectжаЕФtoString
- ЗЕЛиЃК
- зжЗћДЎБОЩэЁЃ
toCharArray
public char[] toCharArray()
- НЋДЫзжЗћДЎзЊЛЛЮЊвЛИіаТЕФзжЗћЪ§зщЁЃ
- ЗЕЛиЃК
- вЛИіаТЗжХфЕФзжЗћЪ§зщЃЌЫќЕФГЄЖШЪЧДЫзжЗћДЎЕФГЄЖШЃЌЖјЧвФкШнБЛГѕЪМЛЏЮЊАќКЌДЫзжЗћДЎБэЪОЕФзжЗћађСаЁЃ
format
public static String format(String format, Object... args)
- ЪЙгУжИЖЈЕФИёЪНзжЗћДЎКЭВЮЪ§ЗЕЛивЛИіИёЪНЛЏзжЗћДЎЁЃ
ЪМжеЪЙгУЕФгябдЛЗОГЪЧгЩ
Locale.getDefault()ЗЕЛиЕФгябдЛЗОГЁЃ- ВЮЪ§ЃК
format- ИёЪНзжЗћДЎargs- дкИёЪНзжЗћДЎжагЩИёЪНЫЕУїЗћв§гУЕФВЮЪ§ЁЃШчЙћЛЙгаИёЪНЫЕУїЗћвдЭтЕФВЮЪ§ЃЌдђКіТдетаЉЖюЭтЕФВЮЪ§ЁЃВЮЪ§ЪЧПЩБфЕФВЂЧвПЩвдЮЊ 0ЁЃВЮЪ§ЕФзюДѓЪ§ФПЪмЁЖJava Virtual Machine SpecificationЁЗЫљЖЈвхЕФ Java Ъ§зщЕФзюДѓЮЌЖШЕФЯожЦЁЃеыЖд null ВЮЪ§ЕФааЮЊвРРЕгк зЊЛЛЁЃ- ЗЕЛиЃК
- вЛИіИёЪНЛЏзжЗћДЎ
- ХзГіЃК
IllegalFormatException- ШчЙћИёЪНзжЗћДЎжаАќКЌЗЧЗЈгяЗЈЃЌгыИјЖЈЕФВЮЪ§ВЛМцШнЕФИёЪНЫЕУїЗћЃЌИёЪНзжЗћДЎИјЖЈЕФВЮЪ§ВЛЙЛЃЌЛђДцдкЦфЫћЗЧЗЈЬѕМўЁЃгаЙиЫљгаПЩФмЕФИёЪНЛЏДэЮѓЕФЙцЗЖЃЌЧыВЮдФ formatter РрЙцЗЖЕФ Details вЛНкЁЃNullPointerException- ШчЙћ format ЮЊ null- ДгвдЯТАцБОПЊЪМЃК
- 1.5
- СэЧыВЮМћЃК
Formatter
format
public static String format(Locale l, String format, Object... args)
- ЪЙгУжИЖЈЕФгябдЛЗОГЁЂИёЪНзжЗћДЎКЭВЮЪ§ЗЕЛивЛИіИёЪНЛЏзжЗћДЎЁЃ
- ВЮЪ§ЃК
l- дкИёЪНЛЏЙ§ГЬжавЊгІгУЕФгябдЛЗОГЁЃШчЙћ l ЮЊ nullЃЌдђВЛНјааБОЕиЛЏЁЃformat- ИёЪНзжЗћДЎargs- дкИёЪНзжЗћДЎжагЩИёЪНЫЕУїЗћв§гУЕФВЮЪ§ЁЃШчЙћЛЙгаИёЪНЫЕУїЗћвдЭтЕФВЮЪ§ЃЌдђКіТдетаЉЖюЭтЕФВЮЪ§ЁЃВЮЪ§ЕФЪ§СПЪЧПЩБфЕФЃЌВЂЧвПЩвдЮЊСуЁЃВЮЪ§ЕФзюДѓЪ§ФПЪмЁЖJava Virtual Machine SpecificationЁЗЫљЖЈвхЕФ Java Ъ§зщЕФзюДѓЮЌЖШЕФЯожЦЁЃеыЖд null ВЮЪ§ЕФааЮЊвРРЕгкзЊЛЛЁЃ- ЗЕЛиЃК
- вЛИіИёЪНЛЏзжЗћДЎ
- ХзГіЃК
IllegalFormatException- ШчЙћИёЪНзжЗћДЎжаАќКЌЗЧЗЈгяЗЈЃЌгыИјЖЈВЮЪ§ВЛМцШнЕФИёЪНЫЕУїЗћЃЌИёЪНзжЗћДЎИјЖЈЕФВЮЪ§ВЛЙЛЃЌЛђДцдкЦфЫћЗЧЗЈЬѕМўЁЃгаЙиЫљгаПЩФмЕФИёЪНЛЏДэЮѓЕФЙцЗЖЃЌЧыВЮдФ formatter РрЙцЗЖЕФ Details вЛНкЁЃNullPointerException- ШчЙћ format ЮЊ null- ДгвдЯТАцБОПЊЪМЃК
- 1.5
- СэЧыВЮМћЃК
Formatter
valueOf
public static String valueOf(Object obj)
- ЗЕЛи
ObjectВЮЪ§ЕФзжЗћДЎБэЪОаЮЪНЁЃ- ВЮЪ§ЃК
obj- вЛИіObjectЁЃ- ЗЕЛиЃК
- ШчЙћВЮЪ§ЮЊ
nullЃЌдђзжЗћДЎЕШгк"null"ЃЛЗёдђЃЌЗЕЛиobj.toString()ЕФжЕЁЃ - СэЧыВЮМћЃК
Object.toString()
valueOf
public static String valueOf(char[] data)
- ЗЕЛи
charЪ§зщВЮЪ§ЕФзжЗћДЎБэЪОаЮЪНЁЃзжЗћЪ§зщЕФФкШнвбБЛИДжЦЃЌКѓајаоИФВЛЛсгАЯьаТДДНЈЕФзжЗћДЎЁЃ- ВЮЪ§ЃК
data-charЪ§зщЁЃ- ЗЕЛиЃК
- вЛИіаТЗжХфЕФзжЗћДЎЃЌЫќБэЪОАќКЌдкзжЗћЪ§зщВЮЪ§жаЕФЯрЭЌзжЗћађСаЁЃ
valueOf
public static String valueOf(char[] data, int offset, int count)
- ЗЕЛи
charЪ§зщВЮЪ§ЕФЬиЖЈзгЪ§зщЕФзжЗћДЎБэЪОаЮЪНЁЃoffsetВЮЪ§ЪЧзгЪ§зщЕФЕквЛИізжЗћЕФЫїв§ЁЃcountВЮЪ§жИЖЈзгЪ§зщЕФГЄЖШЁЃзжЗћЪ§зщЕФФкШнвбБЛИДжЦЃЌКѓајаоИФВЛЛсгАЯьаТДДНЈЕФзжЗћДЎЁЃ- ВЮЪ§ЃК
data- зжЗћЪ§зщЁЃoffset-StringжЕЕФГѕЪМЦЋвЦСПЁЃcount-StringжЕЕФГЄЖШЁЃ- ЗЕЛиЃК
- вЛИізжЗћДЎЃЌЫќБэЪОдкзжЗћЪ§зщВЮЪ§ЕФзгЪ§зщжаАќКЌЕФзжЗћађСаЁЃ
- ХзГіЃК
IndexOutOfBoundsException- ШчЙћoffsetЮЊИКЃЌЛђепcountЮЊИКЃЌЛђепoffset+countДѓгкdata.lengthЁЃ
copyValueOf
public static String copyValueOf(char[] data, int offset, int count)
- ЗЕЛижИЖЈЪ§зщжаБэЪОИУзжЗћађСаЕФзжЗћДЎЁЃ
- ВЮЪ§ЃК
data- зжЗћЪ§зщЁЃoffset- згЪ§зщЕФГѕЪМЦЋвЦСПЁЃcount- згЪ§зщЕФГЄЖШЁЃ- ЗЕЛиЃК
- вЛИі
StringЃЌЫќАќКЌзжЗћЪ§зщЕФжИЖЈзгЪ§зщЕФзжЗћЁЃ
copyValueOf
public static String copyValueOf(char[] data)
- ЗЕЛижИЖЈЪ§зщжаБэЪОИУзжЗћађСаЕФзжЗћДЎЁЃ
- ВЮЪ§ЃК
data- зжЗћЪ§зщЁЃ- ЗЕЛиЃК
- вЛИі
StringЃЌЫќАќКЌзжЗћЪ§зщЕФзжЗћЁЃ
valueOf
public static String valueOf(boolean b)
- ЗЕЛи
booleanВЮЪ§ЕФзжЗћДЎБэЪОаЮЪНЁЃ- ВЮЪ§ЃК
b- вЛИіbooleanЁЃ- ЗЕЛиЃК
- ШчЙћВЮЪ§ЮЊ
trueЃЌЗЕЛивЛИіЕШгк"true"ЕФзжЗћДЎЃЛЗёдђЃЌЗЕЛивЛИіЕШгк"false"ЕФзжЗћДЎЁЃ
valueOf
public static String valueOf(char c)
- ЗЕЛи
charВЮЪ§ЕФзжЗћДЎБэЪОаЮЪНЁЃ- ВЮЪ§ЃК
c- вЛИіcharЁЃ- ЗЕЛиЃК
- вЛИіГЄЖШЮЊ
1ЕФзжЗћДЎЃЌЫќАќКЌВЮЪ§cЕФЕЅИізжЗћЁЃ
valueOf
public static String valueOf(int i)
- ЗЕЛи
intВЮЪ§ЕФзжЗћДЎБэЪОаЮЪНЁЃИУБэЪОаЮЪНЧЁКУЪЧЕЅВЮЪ§ЕФ
Integer.toStringЗНЗЈЗЕЛиЕФНсЙћЁЃ- ВЮЪ§ЃК
i- вЛИіintЁЃ- ЗЕЛиЃК
intВЮЪ§ЕФзжЗћДЎБэЪОаЮЪНЁЃ- СэЧыВЮМћЃК
Integer.toString(int, int)
valueOf
public static String valueOf(long l)
- ЗЕЛи
longВЮЪ§ЕФзжЗћДЎБэЪОаЮЪНЁЃИУБэЪОаЮЪНЧЁКУЪЧЕЅВЮЪ§ЕФ
Long.toStringЗНЗЈЗЕЛиЕФНсЙћЁЃ- ВЮЪ§ЃК
l- вЛИіlongЁЃ- ЗЕЛиЃК
longВЮЪ§ЕФзжЗћДЎБэЪОаЮЪНЁЃ- СэЧыВЮМћЃК
Long.toString(long)
valueOf
public static String valueOf(float f)
- ЗЕЛи
floatВЮЪ§ЕФзжЗћДЎБэЪОаЮЪНЁЃИУБэЪОаЮЪНЧЁКУЪЧЕЅВЮЪ§ЕФ
Float.toStringЗНЗЈЗЕЛиЕФНсЙћЁЃ- ВЮЪ§ЃК
f- вЛИіfloatЁЃ- ЗЕЛиЃК
floatВЮЪ§ЕФзжЗћДЎБэЪОаЮЪНЁЃ- СэЧыВЮМћЃК
Float.toString(float)
valueOf
public static String valueOf(double d)
- ЗЕЛи
doubleВЮЪ§ЕФзжЗћДЎБэЪОаЮЪНЁЃИУБэЪОаЮЪНЧЁКУЪЧЕЅВЮЪ§ЕФ
Double.toStringЗНЗЈЗЕЛиЕФНсЙћЁЃ- ВЮЪ§ЃК
d- вЛИіdoubleЁЃ- ЗЕЛиЃК
doubleВЮЪ§ЕФзжЗћДЎБэЪОаЮЪНЁЃ- СэЧыВЮМћЃК
Double.toString(double)
intern
public String intern()
- ЗЕЛизжЗћДЎЖдЯѓЕФЙцЗЖЛЏБэЪОаЮЪНЁЃ
вЛИіГѕЪМЪБЮЊПеЕФзжЗћДЎГиЃЌЫќгЩРр
StringЫНгаЕиЮЌЛЄЁЃЕБЕїгУ intern ЗНЗЈЪБЃЌШчЙћГивбОАќКЌвЛИіЕШгкДЫ
StringЖдЯѓЕФзжЗћДЎЃЈИУЖдЯѓгЩequals(Object)ЗНЗЈШЗЖЈЃЉЃЌдђЗЕЛиГижаЕФзжЗћДЎЁЃЗёдђЃЌНЋДЫStringЖдЯѓЬэМгЕНГижаЃЌВЂЧвЗЕЛиДЫStringЖдЯѓЕФв§гУЁЃЫќзёбЖдгкШЮКЮСНИізжЗћДЎ
sКЭtЃЌЕБЧвНіЕБs.equals(t)ЮЊtrueЪБЃЌs.intern() == t.intern()ВХЮЊtrueЁЃЫљгазжУцжЕзжЗћДЎКЭзжЗћДЎИГжЕГЃСПБэДяЪНЖМЪЧФкВПЕФЁЃзжЗћДЎзжУцжЕдкЁЖJava Language SpecificationЁЗЕФ §3.10.5 жавбЖЈвхЁЃ
- ЗЕЛиЃК
- вЛИізжЗћДЎЃЌФкШнгыДЫзжЗћДЎЯрЭЌЃЌЕЋЫќБЃжЄРДздзжЗћДЎГижаЁЃ
|
JavaTM 2 Platform Standard Ed. 5.0 |
|||||||||
| ЩЯвЛИіРр ЯТвЛИіРр | ПђМм ЮоПђМм | |||||||||
| еЊвЊЃК ЧЖЬз | зжЖЮ | ЙЙдьЗНЗЈ | ЗНЗЈ | ЯъЯИаХЯЂЃК зжЖЮ | ЙЙдьЗНЗЈ | ЗНЗЈ | |||||||||
ЬсНЛДэЮѓЛђвтМћ
гаЙиИќЖрЕФ API ВЮПМзЪСЯКЭПЊЗЂШЫдБЮФЕЕЃЌЧыВЮдФ Java 2 SDK SE ПЊЗЂШЫдБЮФЕЕЁЃИУЮФЕЕАќКЌИќЯъЯИЕФЁЂУцЯђПЊЗЂШЫдБЕФУшЪіЃЌвдМАзмЬхИХЪіЁЂЪѕгяЖЈвхЁЂЪЙгУММЧЩКЭЙЄзїДњТыЪОР§ЁЃ
АцШЈЫљга 2004 Sun Microsystems, Inc. БЃСєЫљгаШЈРћЁЃ ЧызёЪиаэПЩжЄЬѕПюЁЃСэЧыВЮдФЮФЕЕжиаТЗжЗЂеўВпЁЃ