
Chapter 9. Deployment and Testing - JBoss RULES 4.0.0.11754MR2 manual 英文版使用指南文档
Once you have rules integrated in your application (or ideally before) you will need to plan how to deploy rules along with your application. Typically rules are used to allow changes to application business logic without re-deploying the whole application. This means that the rules must be provided to the application as data, not as part of the application (eg embedded in the classpath).
Drools 3.0 is primarily a Rule Engine, which leaves open many options for rule deployment. The focus of this chapter is on deployment options, and the API. A future version of Drools will have a Rule Server component for managing multiple versions of rules (including locking, and automatic deployment).
As every organisation is subtly different, and different deployment patterns will be needed. Many organisations have (or should have) configuration management processes for changes to production systems. It is best to think of rules as "data" rather then software in that regard. However, as rules can contain a considerable amount of powerful logic, proper procedures should be used in testing and verifying rule changes, and approving changes before exposing them to the world.
In the simplest possible scenario, you would compile and construct a rulebase, and then cache that rulebase. That rulebase can be shared across threads, spawning new working memories to process transactions (working memories are then discarded). This is essentually the stateless mode. To update the rulebase, a new rulebase is loaded, and then swapped out with the cached rulebase (any existing threads that happen to be using the old rulebase will continue to use it until they are finished, in which case it will eventually be garbage collected).
There are many more sophisticated approaches to the above - Drools rule engine is very dynamic, meaning pretty much all the components can be swapped out on the fly (rules, packages) even when there are *existing* working memories in use. For instance rules can be retracted from a rulebase which has many in-use working memories - the RETE network will then be adjusted to remove that rule without having to assert all the facts again. Long running working memories are useful for complex applications where the rule engine builds up knowledge over time to assist with decision making for instance - it is in these cases that the dynamic-ness of the engine can really shine.
One option is to deploy the rules in source form. This leaves the runtime engine (which must include the compiler components) to compile the rules, and build the rule base. A similar approach is to deploy the "PackageDescr" object, which means that the rules are pre-parsed (for syntactic errors) but not compiled into the binary form. Use the PackageBuilder class to achieve this. You can of course use the XML form for the rules if needed.
PackageDescr, PackageBuilder, RuleBaseLoader
This option is the most flexible. In this case, Packages are built from DRL source using PackageBuilder - but it is the binary Package objects that are actually deployed. Packages can be merged together. That means a package containing perhaps a single new rule, or a change to an existing rule, can be built on its own, and then merged in with an existing package in an existing RuleBase. The rulebase can then notify existing working memories that a new rule exists (as the RuleBase keeps "weak" links back to the Working Memory instances that it spawned). The rulebase keeps a list of Packages, and to merge into a package, you will need to know which package you need to merge into (as obviously, only rules from the same package name can be merged together).
Package objects themselves are serializable, hence they can be sent over a network, or bound to JNDI, Session etc.
PackageBuilder, RuleBase, org.drools.rule.Package
Compiled Packages are added to rulebases. RuleBases are serializable, so they can be a binary deployment unit themselves. This can be a useful option for when rulebases are updated as a whole - for short lived working memories. If existing working memories need to have rules changed on the fly, then it is best to deploy Package objects.
RuleBase, RuleBaseLoader
Practically all of the rulebase related objects in Drools are serializable. For a working memory to be serializable, all of your objects must of course be serializable. So it is always possible to deploy remotely, and "bind" rule assets to JNDI as a means of using them in a container environment.
Please note that when using package builder, you may want to check the hasError() flag before continuing deploying your rules (if there are errors, you can get them from the package builder - rather then letting it fail later on when you try to deploy).
In this case, rules are provided to the runtime system in source form. The runtime system contains the drools-compiler component to build the rules. This is the simplest approach.
In this case, rules are build into their binary process outside of the runtime system (for example in a deployment server). The chief advantage of deploying from an outside process is that the runtime system can have minimal dependencies (just one jar). It also means that any errors to do with compiling are well contained and and known before deployment to the running system is attempted.
Use the PackageBuilder class out of process, and then use getPackage() to get the Package object. You can then (for example) serialize the Package object to a file (using standard java serialization). The runtime system, which only needs drools-core, can then load the file using RuleBaseFactory.newRuleBase().addPackage(deserialized package object).
This section contains some suggested deployment scenarios, of course you can use a variety of techologies as alternatives to the ones in the diagram.
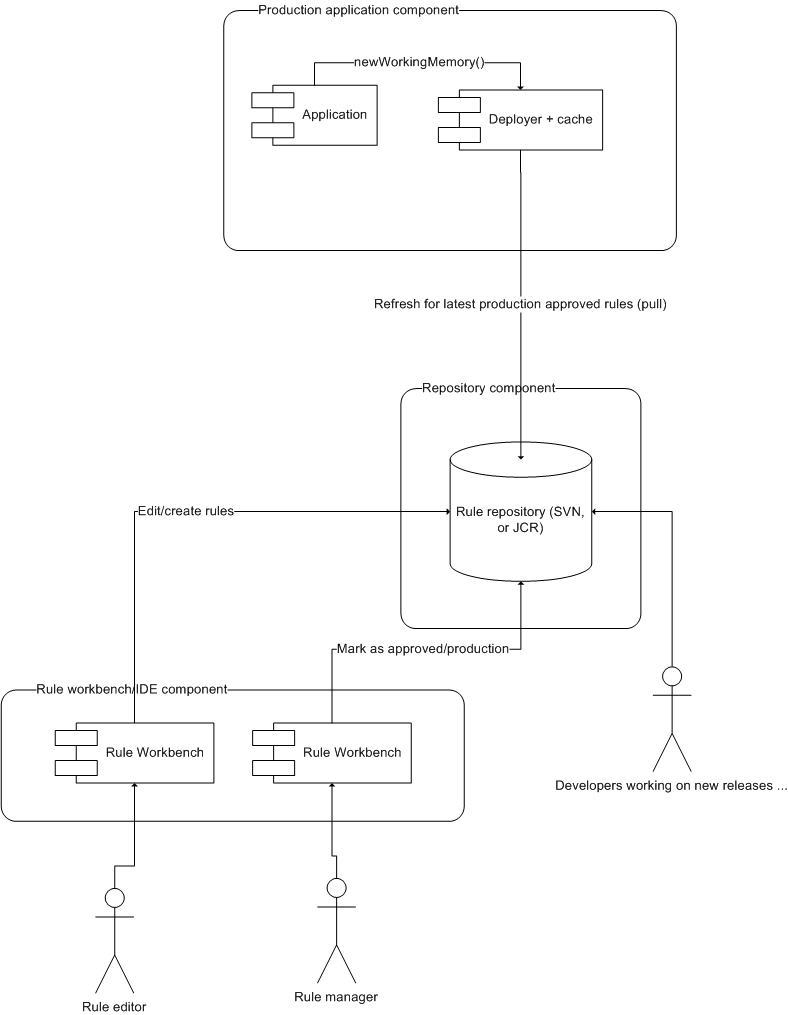
In this scenario, rules are pulled from the rule repository into the runtime system. The repository can be as simple as a file system, or a database. The trigger to pull the rules could be a timed task (to check for changes) or a request to the runtime system (perhaps via a JMX interface). This is possibly the more common scenario.
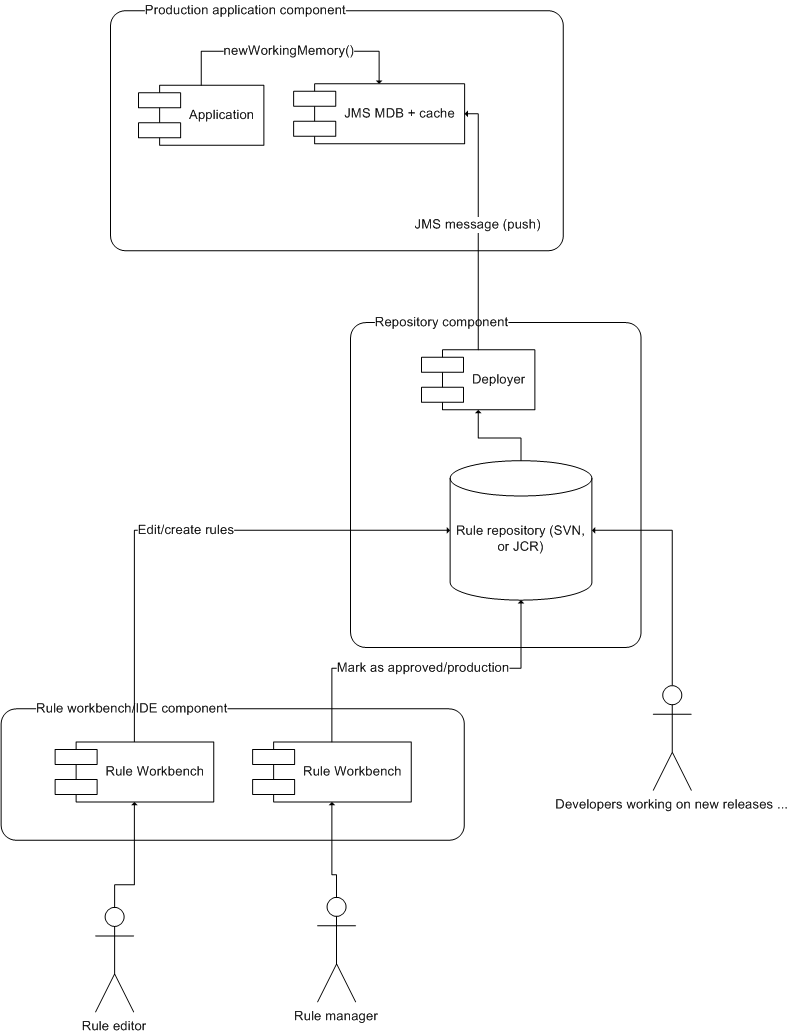
In this scenario, the rule deployment process/repository "pushes" rules into the runtime system (either in source or binary form, as described above). This gives more control as to when the new rules take effect.
A possible deployment pattern for rules are to expose the rules as a web service. There a many ways to achieve this, but possibly the simplest way at present do achieve it is to use an interface-first process: Define the "facts" classes/templates that the rules will use in terms of XML Schema - and then use binding technologies to generate binding objects for the rules to actually operate against. A reverse possibility is to use a XSD/WSDL generator to generate XML bindings for classes that are hand built (which the rules work against). It is expected in a future version there will be an automated tool to expose rules as web services (and possibly use XSDs as facts for the rules to operate on).