
Chapter 7. Performance tuning - JBoss RULES 4.0.0.11754MR2 manual 英文版使用指南文档
In any reasonably complex application, there are many things that may effect performance. The usual advice applies of course (ie don't speculate, measure, profile and plan). In terms of the rule engine, it does its best to be as efficient as possibly, without too much thought needed, most people should not need to read this chapter in detail.
Note that for someone who is using a rule engine of the first time, the most noticable "cost" will be the startup of the rule engine (which is actually compiling the rules) - this problem is easily solved - simply cache the RuleBase instances (or the rule packages) and only update rules as needed (there are many ways to achieve this in your application which will not be covered here).
The remainder of this chapter is considerations on tuning the runtime performance of rules (not compiling), which is where performance often really counts.
As explained in the chapter on the Rete Algorithm, BetaNodes are nodes that have two inputs: the left input (for tuples) and the right input (for single objects). Each beta node has two memories, one for each input: the left memory and the right memory.
So, when a single object arrives at the right input of the node, it tries to match every tuple in the left memory according to the constraints defined for the given BetaNode. Those elements that match are propagated down through the network. The symmetrical behavior happens for when a tuple arrives at the left input of the node. See diagram bellow:
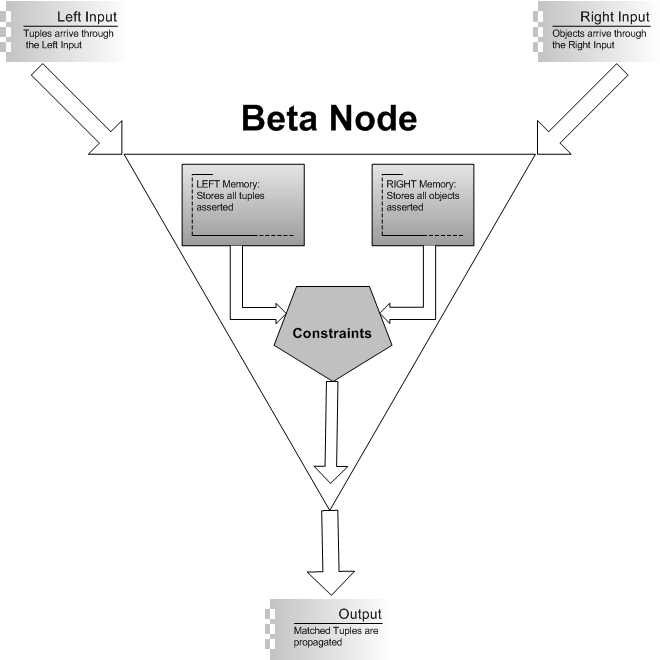
When the number of elements in each of the Beta Node Memories starts to grow, the matching process starts to slow down, as each new element that arrives needs to try to match all the elements in the opposite memory for the given constraints. This process becomes a serious limitation for real systems where thousands of facts are asserted into working memory and where the Rete Network has several Beta Nodes.
One way of minimizing the problem is to index each of the BetaNode memories in a way that when a new element arrives, it does not need to iterate over all elements of the opposite memory in order to find its matches.
So, for example, if we have a Rule like the following:
rule "find brothers"
when
p1: Person( $mother : mother )
p2: Person( mother == $mother )
then
// do something
end
If no indexing is used, each new Person object asserted into working memory will try to match each other previously asserted Person object to find those that have the same mother. So, if we have 1000 Person objects already asserted into working memory, and we assert a new one, the new one will try to match each of the 1000 previously asserted objects.
If we index BetaNode memories by the “mother” attribute, though, when a new Person is asserted into memory, it will try to match only the previously asserted objects that have the same mother attribute, in a very efficient way using the previously built index. So, if the new object has only one brother previously asserted into memory, it will match only one object, avoiding the 999 tries that would fail.
Drools implements BetaNode indexing exactly as described above in order to boost performance. The BetaNode indexing is enabled by default and users usually don’t need to worry about it. Although, for specific situations where a user has a limited amount of memory or for some reason does not want to incur in the indexing overhead, indexing can be disabled for each of the memories, by setting the following system properties to false:
org.drools.reteoo.beta.index-left org.drools.reteoo.beta.index-right For example: ..when you launch the application (or in the container as appropriate). -Dorg.drools.reteoo.beta.index-right=false -Dorg.drools.reteoo.beta.index-left=false
A good way to understand what happens when indexing is used is to make an analogy to databases systems. As we all know, indexing is a great mechanism for performance improvements on database queries, but also adds an overhead to other operations like insert, updates and deletes. Also, there is a memory consumption cost involved. A well planned set of indexes is essential for most enterprise applications and the responsible for defining them is usually the DBA. Once indexes are defined, when a query is executed against that database, a query planner component is used by database systems to estimate the best plan to run the query with the best performance, sometimes using the index, sometimes not.
Working memory has the same issues and same thoughts are valid here. Drools implements an automatic indexing strategy to index beta node memories. Just to have some data to understand the consequences of it, lets use Manners 64 benchmark test results on a Pentium IV 3 Ghz HT machine with 1.0 Gb memory. This is not really a detailed benchmark test, but simply some rough numbers in order to make the scenario easier to understand:
Manners 64 without indexes: 135000 millisec to run Manners 64 with BetaNode indexes: 10078 millisec to run on average
It is obvious by the previous run times that indexes overall benefits pays off the overhead to keep them, at least in terms of performance. We are not analyzing limited memory environments here.
Although, every system has its own peculiarities and sometimes it is possible to do some fine tuning on performance. For example, in our Manners 64 example, if we disable the right memory indexing we would have the following result:
Manners 64 with BetaNode indexing only for left memory: 142000 millisec to run on average
The above is even worse than no using any indexing. This happens clearly because for Manners 64, the left indexing overhead is bigger than its benefit. So, if we do the contrary, leaving right indexing enabled and disabling the left indexing, we get the following result:
Manners 64 with BetaNode indexing only for right memory: 8765 millisec to run on average
So, we have the best scenario now. For Manners 64, the best would be to disable left indexing, leaving only right indexing enabled.
Another tip to tune performance when using indexing is always to write your rules in a way that the most restrictive constraints are declared before the less restrictive ones in your rule. For example, if you have a rule with a column like this:
Employee (department == $aDepartment, name == $aName)
Rewriting it as shown bellow will probably give you a better performance, as “name” is probably a more restrictive constraint than “department”:
Employee (name == $aName, department == $aDepartment)
(Unless you work in an organisation where there are more departments then employees, which could well be the case in a Government organisation ;)
Some other improvements are being developed for Drools in this area and will be documented as they become available in future versions.
For this section, large rulesets are define as the following
- 1-500 - small ruleset
- 500-2000 - medium ruleset
- 2000+ - large ruleset
- 10,000 - extremely large ruleset
There are some cases where a rule engine has to handle 500,000 or 1 million rules. Those are primarily machine learning and AI systems, where a rule engine produces new rules, terms and facts at execution time. Those topics are beyond the scope of the documentation and aren't covered. The techniques described are focused on business rules.
The first thing to do is identify why there are so many rules and whether or not rewriting the rules can solve the problem. There's a couple of things to look for.
- Do the rules have a lot of constant values hard coded in the conditions?
- Is the domain model a huge flat spreadsheet with 100+ columns?
- Do most of the rules share the same conditions?
- Can the logic be divided into stages?
If you answer yes to any of the 4 questions, chances are you can solve the issue with changing the rules. Managing 100,000 rules or even 1,000,000 rules is a huge headache, so try to avoid it. Examine the rules and see if it matches any of the following scenarios.
If
customer.account == "abcd"
customer.type == "basic"
.....
Then
// do something
The basic problem with rules sample above, is the rules have most of the values hard coded. If the average customer has 50 rules and there's 40 million customers, the system has 200 million rules. Let's use a more concrete example to flesh this out.
If
customer.accountId == "peter"
customer.type == "level2"
customer.favoriateActor == "jackie chan"
Then
recommend movies with jackie chan
If
customer.accountId == "peter"
customer.type == "level2"
customer.favoriateActor == "jet li"
Then
recommend movies with jet li
Looking at the example, the first to question ask is "do these kinds of rules apply to all customers?" If it does, the first condition in the rule "customer.accountId" is pointless. It's pointless because all rules of this type will have that condition. Although the accountId changes, the rule can effectively ignore it. If we rewrite the rule this way, the rule can apply to any customer that likes jackie chan and jet li.
If
customer.type == "level2"
customer.favoriateActor == "jackie chan"
Then
recommend movies with jackie chan
If
customer.type == "level2"
customer.favoriateActor == "jet li"
Then
recommend movies with jet li
The reason we do this is straight forward. The rules reason over data. Having a ton of rules with the customer's accountId hard coded doesn't do any good, because we want the rule engine to only evaluate the active sessions. We don't want to load all the customers into the rule engine. We can take it a step further and make the rule more general.
If
customer.type == "level2"
customer.accountId ?id // bind the account id to a variable
favorites.accountId ?id // find the list of favorites by the account id
Then
recommend all items in the favorites
With this change, it can reduce the number of rules significantly. This is one reason the RETE approach is often called "data driven approach". Let's take this example a bit further and define 10 types of customers from level1 to level10. Say we run a mega online store and customers can define their favorites in each of the categories (books, videos, music, toys, electronics, clothing). What happens if a customer has different levels for each category. Using the hard coded approach, one might have to add more rules. If we change the rule and make it more generalized, the same rule can handle multiple categories.
If
recommendation.level ?lvl // bind the recommendation level to a variable
recommendation.category ?rcat // bind the recommendation category
customer.accountId ?id // bind the account id to a variable
favorites.accountId ?id // find the list of favorites by the account id
favorites.category ?rcat // match favorite to recommendation category
favorites.level ?lvl // match the favorite level to recommendation level
Then
recommend all items in the favorites
So what is the cost of making the rule dynamic and data driven? Obviously, hard coding a rule is going to be faster than making it generalized, but the performance delta should be small. In the case where a ruleset is small, the hard coded approach may have a slight performance lead. Why is that? Lets look at 2 different types of rule engines: procedural and RETE.
In a procedural engine, one can build a decision tree and end the evaluation once the data fails to satisfy the conditions at a given level. As the rule count increases, there are more rules the engine has to evaluate. In a procedural approach, the rules have to be sequenced in the optimal order to get the best results. The limitation of sorting the rules in optimal sequence is that many cases it's not possible to pre-sort. If we use a RETE rule engine, the hard coded rules result in fewer joins for a small number of rules. As the rule count grows, the single rule will perform better. The equation to estimate the threshold where the generalized form is faster than hard coding the constants.
bn = join nodes, lf = left facts, rf = right facts, ae = average number of evaluation descending from the object type node for a random sample, f = facts, hd = hard coded constants in the rules, general = generalized form using joins
general( sum( bn(lf * rf) ) + sum(ae * f) ) < hd( sum( bn(lf * rf) ) + sum(ae * f) )
The best way to quantify the threshold is to write rules in both formats and run a series of tests. Given that most projects are under tight schedules, developers don't always have time to do this. The other common problem is using really large flat objects. In a nutshell, using large flat objects leads to the same problem as hard coding the constants in the rules. The solution to the problem is to change the domain objects, such that it models the business concepts in a concise manner. That isn't always an option.
When most of the rules share the same conditions, there's two solutions. The best solution is to rewrite the rules to use chaining. Identify the common conditions and extract it into a generalized rule. The generalized rule then trigger subsequent rules by asserting a new fact. Often this can reduce the rules by an order of magnitude or more. The second option is to put common conditions at the beginning of the rule. What this does is it allows RETE rule engines to share those nodes. When the nodes are shared, it reduces the cost from a memory and performance perspective.
If the ruleset can be divided into smaller chunks, it's a good idea to divide it into discrete stages and load each ruleset on a different JVM or server. Depending on the situation, this may not be an option. So what can you do when the ruleset is large and rewriting the rules isn't an option?
The only viable option is to scale the hardware and use a different JVM. This means using 64bit JVM from SUN, IBM or BEA JRockit on a machine with atleast 8Gb RAM. Depending on the ruleset, the system may need more RAM.