
Chapter 12. Logging - JBoss JBPM 3.0.4 userguide 英文版文档
The purpose of logging is to keep track of the history of a process execution. As the runtime data of a process execution changes, all the delta's are stored in the logs.
Process logging, which is covered in this chapter, is not to be confused with software logging. Software logging traces the execution of a software program (usually for debugging purposes). Process logging traces the execution of process instances.
There are various use cases for process logging information. Most obvious is the consulting of the process history by participants of a process execution.
Another use case is Business Activity Monitoring (BAM). BAM will query or analyse the logs of process executions to find usefull statistical information about the business process. E.g. how much time is spend on average in each step of the process ? Where are the bottlenecks in the process ? ... This information is key to implement real business process management in an organisation. Real business process management is about how an organisation manages their processes, how these are supported by information technology *and* how these two improve the other in an iterative process.
Next use case is the undo functionality. Process logs can be used to implement the undo. Since the logs contain the delta's of the runtime information, the logs can be played in reverse order to bring the process back into a previous state.
Logs are produced by jBPM components while it is running process executions. But also users can insert process logs. A log entry is a java object that inherits from org.jbpm.logging.log.ProcessLog. Process log entries are added to the LoggingInstance. The LoggingInstance is an optional extension of the ProcessInstance.
Various kinds of logs are generated by jBPM : graph execution logs, context logs and task management logs. For more information about the specific data contained in those logs, we refer to the javadocs. A good starting point is the class org.jbpm.logging.log.ProcessLog since from that class you can navigate down the inheritance tree.
The LoggingInstance will collect all the log entries. When the ProcessInstance is saved, all the logs in the LoggingInstance will be flushed to the database. The logs-field of a ProcessInstance is not mapped with hibernate to avoid that logs are retrieved from the database in each transactions. Each ProcessLog is made in the context of a path of execution (Token) and hence, the ProcessLog refers to that token. The Token also serves as an index-sequence generator for the index of the ProcessLog in the Token. This will be important for log retrieval. That way, logs that are produced in subsequent transactions will have sequential sequence numbers. (wow, that a lot of seq's in there :-s ).
For deployments where logs are not important, it suffices to get rid of the optional LoggingDefinition in the ProcessDefinition. That will prevent LoggingInstances from being captured and hence no logs will be maintained. We will add more fine grained configuration control over logging later on. See jira issue 'log level configuration'.
The API method for adding process logs is the following.
public class LoggingInstance extends ModuleInstance {
...
public void addLog(ProcessLog processLog) {...}
...
}The UML diagram for logging information looks like this:
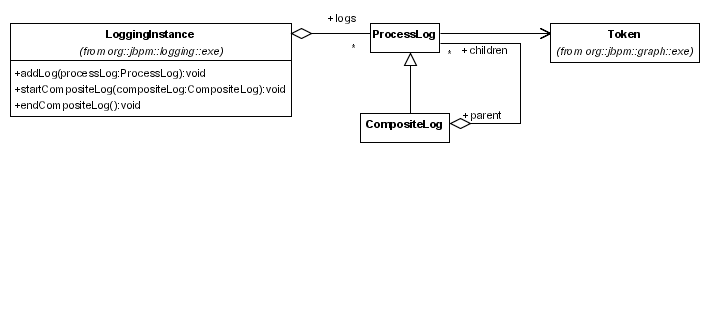
A CompositeLog is a special kind of log entry. It serves as a parent log for a number of child logs, thereby creating the means for a hierarchical structure in the logs. The API for inserting a log is the following.
public class LoggingInstance extends ModuleInstance {
...
public void startCompositeLog(CompositeLog compositeLog) {...}
public void endCompositeLog() {...}
...
}The CompositeLogs should always be called in a try-finally-block to make sure that the hierarchical structure of logs is consistent. For example:
startCompositeLog(new MyCompositeLog());
try {
...
} finally {
endCompositeLog();
}As said before, logs cannot be retrieved from the database by navigating the LoggingInstance to its logs. Instead, logs of a process instance should always be queried from the database. The LoggingSession has 2 methods that serve this purpose.
The first method retrieves all the logs for process instance. These logs will be grouped by token in a Map. The map will associate a List of ProcessLogs with every Token in the process instance. The list will contain the ProcessLogs in the same ordered as they were created.
public class LoggingSession {
...
public Map findLogsByProcessInstance(long processInstanceId) {...}
...
}The second method retrieves the logs for a specific Token. The returned list will contain the ProcessLogs in the same ordered as they were created.
public class LoggingSession {
public List findLogsByToken(long tokenId) {...}
...
}Sometimes you may want to apply data warehousing techniques to the jbpm process logs. Data warehousing means that you create a separate database containing the process logs to be used for various purposes.
There may be many reasons why you want to create a data warehouse with the process log information. Sometimes it might be to offload heavy queryies from the 'live' production database. In other situations it might be to do some extensive analysis. Data warehousing even might be done on a modified database schema which is optimized for its purpose.
In this section, we only want to propose the technique of warehousing in the context of jBPM. The purposes are too diverse, preventing a generic solution to be included in jBPM that could cover all those requirements.